- жµПиІИ: 4595364 жђ°
- жАІеИЂ:

- жЭ•иЗ™: ж≠¶ж±Й
-

жЦЗзЂ†еИЖз±ї
з§ЊеМЇзЙИеЭЧ
- жИСзЪДиµДиЃѓ ( 0)
- жИСзЪДиЃЇеЭЫ ( 0)
- жИСзЪДйЧЃз≠Ф ( 0)
е≠Шж°£еИЖз±ї
- 2013-03 ( 15)
- 2013-02 ( 44)
- 2013-01 ( 243)
- жЫіе§Ъе≠Шж°£...
жЬАжЦ∞иѓДиЃЇ
-
x70740692пЉЪ
жИСдєЯжШѓиИЖжГЕз≥їзїЯиЛ¶йАЉйЪЊеБЪ
зљСзїЬиИЖжГЕдњ°жБѓеИЖжЮРз≥їзїЯвАФвАФпЉИ1пЉЙ -
еЛЗж∞Фй≠ДеКЫпЉЪ
еХ•еХКпЉБж≤°дїАдєИдњ°жБѓ
ArcGIS for Server 10.1жЩЇиГљжФѓжМБдЇСзЪДжЮґжЮД(дЄК) -
ињЯжЭ•зЪДй£ОпЉЪ
еЊИдЄНйФЩпЉМеАЉеЊЧе≠¶дє†пЉМйЭЮеЄЄжДЯи∞ҐжВ®зїЩдЇЖжИСдїђињЩдєИе•љзЪДиµДжЇР
жЬАжЦ∞ иЈЯжИСе≠¶spring3 зФµе≠Рдє¶дЄЛиљљ -
linfanneпЉЪ
¬† еУ≠дЇЖпЉМ жЬЙдЄАдЄ™еЬ∞жЦєеЖЩйФЩдЇЖпЉМ иЈЯдЇЖ2дЄ™е§Ъе∞ПжЧґдї£з†БжЙНжЙЊеИ∞еОЯеЫ†& ...
Spring MVC+Freemarker+JavascriptзЪДе§Ъиѓ≠и®АпЉИеЫљйЩЕеМЦi18n/жЬђеЬ∞еМЦпЉЙеТМдЄїйҐШпЉИThemeпЉЙеЃЮзО∞ -
linfanneпЉЪ
жЧ†жХ∞зЪДй≤ЬиК±пЉМе§Ъиѓ≠и®АжЪВжЧґдЄНиАГиЩСпЉМе§ЪдЄїйҐШеИЪе•љзФ®еИ∞пЉМжИСдЄАиИђйГљдЄНеЫЮеЄЦпЉМ ...
Spring MVC+Freemarker+JavascriptзЪДе§Ъиѓ≠и®АпЉИеЫљйЩЕеМЦi18n/жЬђеЬ∞еМЦпЉЙеТМдЄїйҐШпЉИThemeпЉЙеЃЮзО∞
еЫЊзЪДеЇФзФ®иѓ¶иІ£-жХ∞жНЃзїУжЮД
ж¶Вињ∞
жЬАе∞ПзФЯжИРж†СвАФвАФжЧ†еРСињЮйАЪеЫЊзЪДжЙАжЬЙзФЯжИРж†СдЄ≠жЬЙдЄАж£µиЊєзЪДжЭГеАЉжАїеТМжЬАе∞ПзЪДзФЯжИРж†С
жЛУжЙСжОТеЇПвАФвАФзФ±еБПеЇПеЃЪдєЙеЊЧеИ∞жЛУжЙСжЬЙеЇПзЪДжУНдљЬдЊњжШѓжЛУжЙСжОТеЇПгАВеїЇзЂЛж®°еЮЛжШѓAOVзљС
еЕ≥йФЃиЈѓеЊДвАФвАФеЬ®AOE-зљСдЄ≠жЬЙдЇЫжіїеК®еПѓдї•еєґи°МеЬ∞ињЫи°МпЉМжЙАдї•еЃМжИРеЈ•з®ЛзЪДжЬАзЯ≠жЧґйЧіжШѓдїОеЉАеІЛзВєеИ∞еЃМжИРзВєзЪДжЬАйХњиЈѓеЊДзЪДйХњеЇ¶пЉМиЈѓеЊДйХњеЇ¶жЬАйХњзЪДиЈѓеЊДеПЂеБЪеЕ≥йФЃиЈѓеЊД(Critical Path)гАВ
жЬАзЯ≠иЈѓеЊДвАФвАФжЬАзЯ≠иЈѓеЊДйЧЃйҐШжШѓеЫЊз†Фз©ґдЄ≠зЪДдЄАдЄ™зїПеЕЄзЃЧж≥ХйЧЃйҐШпЉМ жЧ®еЬ®еѓїжЙЊеЫЊпЉИзФ±зїУзВєеТМиЈѓеЊДзїДжИРзЪДпЉЙдЄ≠дЄ§зїУзВєдєЛйЧізЪДжЬАзЯ≠иЈѓеЊДгАВ
1.жЬАе∞ПзФЯжИРж†С
1.1 йЧЃйҐШиГМжЩѓпЉЪ
еБЗиЃЊи¶БеЬ®nдЄ™еЯОеЄВдєЛйЧіеїЇзЂЛйАЪдњ°иБФзїЬзљСпЉМеИЩињЮйАЪnдЄ™еЯОеЄВеП™йЬАи¶БnвАФ1жЭ°зЇњиЈѓгАВињЩжЧґпЉМиЗ™зДґдЉЪиАГиЩСињЩж†ЈдЄАдЄ™йЧЃйҐШпЉМе¶ВдљХеЬ®жЬАиКВзЬБзїПиієзЪДеЙНжПРдЄЛеїЇзЂЛињЩдЄ™йАЪдњ°зљСгАВеЬ®жѓПдЄ§дЄ™еЯОеЄВдєЛйЧійГљеПѓдї•иЃЊзљЃдЄАжЭ°зЇњиЈѓпЉМзЫЄеЇФеЬ∞йГљи¶БдїШеЗЇдЄАеЃЪзЪДзїПжµОдї£дїЈгАВnдЄ™еЯОеЄВдєЛйЧіпЉМжЬАе§ЪеПѓиГљиЃЊзљЃn(n-1)/2жЭ°зЇњиЈѓпЉМйВ£дєИпЉМе¶ВдљХеЬ®ињЩдЇЫеПѓиГљзЪДзЇњиЈѓдЄ≠йАЙжЛ©n-1жЭ°пЉМдї•дљњжАїзЪДиАЧиієжЬАе∞СеСҐ?
1.2 еИЖжЮРйЧЃйҐШпЉИеїЇзЂЛж®°еЮЛпЉЙпЉЪ
еПѓдї•зФ®ињЮйАЪзљСжЭ•и°®з§ЇnдЄ™еЯОеЄВдї•еПКnдЄ™еЯОеЄВйЧіеПѓиГљиЃЊзљЃзЪДйАЪдњ°зЇњиЈѓпЉМеЕґдЄ≠зљСзЪДй°ґзВєи°®з§ЇеЯОеЄВпЉМиЊєи°®з§ЇдЄ§еЯОеЄВдєЛйЧізЪДзЇњиЈѓпЉМиµЛдЇОиЊєзЪДжЭГеАЉи°®з§ЇзЫЄеЇФзЪДдї£дїЈгАВеѓєдЇОnдЄ™й°ґзВєзЪДињЮйАЪзљСеПѓдї•еїЇзЂЛиЃЄе§ЪдЄНеРМзЪДзФЯжИРж†СпЉМжѓПдЄАж£µзФЯжИРж†СйГљеПѓдї•жШѓдЄАдЄ™йАЪдњ°зљСгАВеН≥жЧ†еРСињЮйАЪеЫЊзЪДзФЯжИРж†СдЄНжШѓеФѓдЄАзЪДгАВињЮйАЪеЫЊзЪДдЄАжђ°йБНеОЖжЙАзїПињЗзЪДиЊєзЪДйЫЖеРИеПКеЫЊдЄ≠жЙАжЬЙй°ґзВєзЪДйЫЖеРИе∞±жЮДжИРдЇЖиѓ•еЫЊзЪДдЄАж£µзФЯжИРж†СпЉМеѓєињЮйАЪеЫЊзЪДдЄНеРМйБНеОЖпЉМе∞±еПѓиГљеЊЧеИ∞дЄНеРМзЪДзФЯжИРж†СгАВ
еЫЊ G5жЧ†еРСињЮйАЪеЫЊзЪДзФЯжИРж†СдЄЇ(a)гАБ(b)еТМ(c)еЫЊжЙАз§ЇпЉЪ
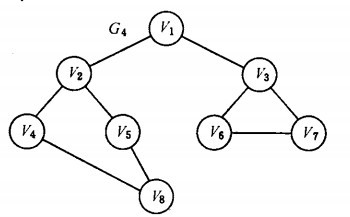
G5
G5зЪДдЄЙж£µзФЯжИРж†СпЉЪ
еПѓдї•иѓБжШОпЉМеѓєдЇОжЬЙn дЄ™й°ґзВєзЪДжЧ†еРСињЮйАЪеЫЊпЉМжЧ†иЃЇеЕґзФЯжИРж†СзЪД嚥жАБе¶ВдљХпЉМжЙАжЬЙзФЯжИРж†СдЄ≠йГљжЬЙдЄФдїЕжЬЙnпЉН1 жЭ°иЊєгАВ
1.3жЬАе∞ПзФЯжИРж†СзЪДеЃЪдєЙпЉЪ
е¶ВжЮЬжЧ†еРСињЮйАЪеЫЊжШѓдЄАдЄ™зљСпЉМйВ£дєИпЉМеЃГзЪДжЙАжЬЙзФЯжИРж†СдЄ≠ењЕжЬЙдЄАж£µиЊєзЪДжЭГеАЉжАїеТМжЬАе∞ПзЪДзФЯжИРж†СпЉМжИСдїђзІ∞ињЩж£µзФЯжИРж†СдЄЇжЬАе∞ПзФЯжИРж†СпЉМзЃАзІ∞дЄЇжЬАе∞ПзФЯжИРж†СгАВ
жЬАе∞ПзФЯжИРж†СзЪДжАІиі®пЉЪ
еБЗиЃЊN=(V,{ E}) жШѓдЄ™ињЮйАЪзљСпЉМUжШѓй°ґзВєйЫЖеРИVзЪДдЄАдЄ™йЭЮз©Їе≠РйЫЖпЉМиЛ•пЉИu,vпЉЙжШѓдЄ™дЄАжЭ°еЕЈжЬЙжЬАе∞ПжЭГеАЉ(дї£дїЈ)зЪДиЊєпЉМеЕґдЄ≠ пЉМ
пЉМ
еИЩењЕе≠ШеЬ®дЄАж£µеМЕеРЂиЊєпЉИu,vпЉЙзЪДжЬАе∞ПзФЯжИРж†СгАВ
1.4 иІ£еЖ≥жЦєж°ИпЉЪ
дЄ§зІНеЄЄзФ®зЪДжЮДйА†жЬАе∞ПзФЯжИРж†СзЪДзЃЧж≥ХпЉЪжЩЃйЗМеІЖпЉИPrimпЉЙеТМеЕЛй≤БжЦѓеН°е∞ФпЉИKruskalпЉЙгАВдїЦдїђйГљеИ©зФ®дЇЖжЬАе∞ПзФЯжИРж†СзЪДжАІиі®
1.жЩЃйЗМеІЖпЉИPrimпЉЙзЃЧж≥ХпЉЪжЬЙзЇњеИ∞зВєпЉМйАВеРИ茺箆еѓЖгАВжЧґйЧіе§НжЭВеЇ¶O(N^2)
еБЗиЃЊGпЉЭпЉИVпЉМEпЉЙдЄЇињЮйАЪеЫЊпЉМеЕґдЄ≠V дЄЇзљСеЫЊдЄ≠жЙАжЬЙй°ґзВєзЪДйЫЖеРИпЉМE дЄЇзљСеЫЊдЄ≠жЙАжЬЙеЄ¶жЭГиЊєзЪДйЫЖеРИгАВиЃЊзљЃдЄ§дЄ™жЦ∞зЪДйЫЖеРИU еТМTпЉМеЕґдЄ≠
йЫЖеРИUпЉИй°ґзВєйЫЖпЉЙзФ®дЇОе≠ШжФЊG зЪДжЬАе∞ПзФЯжИРж†СдЄ≠зЪДй°ґзВєпЉМ
йЫЖеРИT пЉИиЊєйЫЖеРИпЉЙе≠ШжФЊG зЪДжЬАе∞ПзФЯжИРж†СдЄ≠зЪДиЊєгАВ
T пЉМUзЪДеИЭеІЛзКґжАБпЉЪдї§йЫЖеРИU зЪДеИЭеАЉдЄЇUпЉЭ{u1}пЉИеБЗиЃЊжЮДйА†жЬАе∞ПзФЯжИРж†СжЧґпЉМдїОй°ґзВєu1 еЗЇеПСпЉЙпЉМйЫЖеРИT зЪДеИЭеАЉдЄЇTпЉЭ{}гАВ
Prim зЃЧж≥ХзЪДжАЭжГ≥жШѓпЉЪдїОжЙАжЬЙuвИИUпЉМvвИИVпЉНU зЪДиЊєдЄ≠пЉМйАЙеПЦеЕЈжЬЙжЬАе∞ПжЭГеАЉзЪДиЊєпЉИuпЉМvпЉЙвИИEпЉМе∞Жй°ґзВєv еК†еЕ•йЫЖеРИU дЄ≠пЉМе∞ЖиЊєпЉИuпЉМvпЉЙеК†еЕ•йЫЖеРИT дЄ≠пЉМе¶Вж≠§дЄНжЦ≠йЗНе§НпЉМзЫіеИ∞UпЉЭV жЧґпЉМжЬАе∞ПзФЯжИРж†СжЮДйА†еЃМжѓХпЉМињЩжЧґйЫЖеРИT дЄ≠еМЕеРЂдЇЖжЬАе∞ПзФЯжИРж†СзЪДжЙАжЬЙиЊєгАВ
Prim зЃЧж≥ХеПѓзФ®дЄЛињ∞ињЗз®ЛжППињ∞пЉМеЕґдЄ≠зФ®wuv и°®з§Їй°ґзВєu дЄОй°ґзВєv иЊєдЄКзЪДжЭГеАЉгАВпЉИ1пЉЙUпЉЭ{u1},T={};
пЉИ2пЉЙwhile (UвЙ†V)do
(uпЉМv)пЉЭmin{wuvпЉЫuвИИUпЉМvвИИVпЉНU }
TпЉЭTпЉЛ{(uпЉМv)}
UпЉЭUпЉЛ{v}
пЉИ3пЉЙзїУжЭЯгАВ
жМЙзЕІPrim жЦєж≥ХпЉМдїОй°ґзВє1 еЗЇеПСпЉМиѓ•зљСзЪДжЬАе∞ПзФЯжИРж†СзЪДдЇІзФЯињЗз®Ле¶ВеЫЊпЉЪ

дЄЇеЃЮзО∞Prim зЃЧж≥ХпЉМйЬАиЃЊзљЃдЄ§дЄ™иЊЕеК©closedgeпЉМзФ®жЭ•дњЭе≠ШUеИ∞йЫЖеРИVпЉНU зЪДеРДдЄ™й°ґзВєдЄ≠еЕЈжЬЙжЬАе∞ПжЭГеАЉзЪДиЊєзЪДжЭГеАЉгАВеѓєжѓПдЄ™ViвИИпЉИV-U пЉЙеЬ®иЊЕеК©жХ∞зїДдЄ≠е≠ШеЬ®дЄАдЄ™зЫЄеЇФзЪДеИЖйЗПclosedge[i-1],еЃГеМЕжЛђдЄ§дЄ™еЯЯпЉЪ
typedefstructArcNode
{
- intadjvex;//adjexеЯЯе≠ШеВ®иѓ•иЊєдЊЭйЩДзЪДеЬ®UдЄ≠зЪДй°ґзВє
- VrTypelowcost;//lowcostеЯЯе≠ШеВ®иѓ•иЊєдЄКзЪДжЭГйЗН
- }closedge[MAX_VERTEX_NUM];
-

еИЭеІЛзКґжАБжЧґпЉМUпЉЭ{v1}(u1 дЄЇеЗЇеПСзЪДй°ґзВє),еИЩеИ∞V-U дЄ≠еРДй°єдЄ≠жЬАе∞ПзЪДиЊєпЉМеН≥дЊЭйЩДй°ґзВєv1зЪДеРДжЭ°иЊєдЄ≠пЉМжЙЊеИ∞дЄАжЭ°дї£дїЈжЬАе∞ПзЪДиЊєпЉИu0пЉМv0пЉЙ= пЉИ1пЉМ3пЉЙдЄЇзФЯжИРж†СдЄКдЄАжЭ°иЊєгАВ
еРМжЧґе∞Жv0пЉИ=v3пЉЙеєґеЕ•йЫЖеРИUдЄ≠гАВзДґеРОдњЃжФєиЊЕеК©жХ∞зїДзЪДеАЉгАВ
1пЉЙе∞Жclosedge[2].lowcost = 0пЉЫ//и°®з§Їй°ґзВєV3дЄЙеЈ≤зїПеєґеЕ•U
2) зФ±дЇОиЊєпЉИv2,v3пЉЙзЪДжЭГеАЉе∞ПдЇОclosedge[1].lowcostпЉМжХЕйЬАдњЃжФєclosedge[1]дЄЇиЊєпЉИv2,v3пЉЙеПКеЕґжЭГеАЉпЉМеРМзРЖдњЃжФєclosedge[4]пЉМclosedge[5].
closedge[1].adjvex = 3.
closedge[1].lowcost = 5.
closedge[4].adjvex = 1.
closedge[4].lowcost = 5.
closedge[5].adjvex = 3.
closedge[5].lowcost = 6.
дї•ж≠§з±їжО®пЉМзЫіиЗ≥U = V;
дЄЛеЫЊ зїЩеЗЇдЇЖеЬ®зФ®дЄКињ∞зЃЧж≥ХжЮДйА†зљСеЫЊ7.16зЪДжЬАе∞ПзФЯжИРж†СзЪДињЗз®ЛдЄ≠пЉЪ
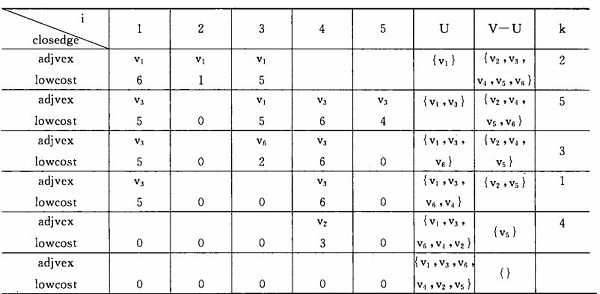
Prim зЃЧж≥ХеЃЮзО∞пЉЪ
жМЙзЕІзЃЧж≥Хж°ЖжЮґ:
пЉИ1пЉЙUпЉЭ{u1},T={};
пЉИ2пЉЙwhile (UвЙ†V)do
(uпЉМv)пЉЭmin{wuvпЉЫuвИИUпЉМvвИИVпЉНU }
TпЉЭTпЉЛ{(uпЉМv)}
UпЉЭUпЉЛ{v}
пЉИ3пЉЙзїУжЭЯгАВ
ељУжЧ†еРСзљСйЗЗзФ®дЇМзїіжХ∞зїДе≠ШеВ®зЪДйВїжО•зЯ©йШµе≠ШеВ®жЧґпЉМPrim зЃЧж≥ХзЪДC иѓ≠и®АеЃЮзО∞дЄЇпЉЪ
//иЃ∞ељХдїОй°ґзВєйЫЖUеИ∞VвАФUзЪДдї£дїЈжЬАе∞ПзЪДиЊєзЪДиЊЕеК©жХ∞зїДеЃЪдєЙпЉЪ
// struct{
// VertexType adjvexпЉЫ
// VRType lowcostпЉЫ
// }closedge[ MAX_VERTEX_NUM ]
void MiniSpanTree_PRIM (MGraph GпЉМVertexType u){
//зФ®жЩЃйЗМеІЖзЃЧж≥ХдїОзђђuдЄ™й°ґзВєеЗЇеПСжЮДйА†зљСGзЪДжЬАе∞ПзФЯжИРж†СTпЉМиЊУеЗЇTзЪДеРДжЭ°иЊєгАВ
k =LocateVex(GпЉМu)пЉЫ
for(j=0пЉЫ j<G.vexnumпЉЫ ++j)
if(j!=k) closedge[j] ={u ,G.arcs[k][j].adj}; // {adjvex , lowcost}
closedge[k].lowcost =0пЉЫ //еИЭеІЛпЉМU={u}
for( i=1пЉЫi<G.vexnumпЉЫ++i){ //йАЙжЛ©еЕґдљЩG.vexnum-1дЄ™й°ґзВє
k=minimum(closedge)пЉЫ
printf(closedge[k].adjvex, G.vexs[k]);//иЊУеЗЇзФЯжИРж†СзЪДиЊє
//зђђkй°ґзВєеєґеЕ•UйЫЖ
closedge[k].lowcost=0;
for(j=0; j<G.vexnum; ++j)
if (G.acrs[k][j].adj<closedge[j].lowcost) closedge[j]={G.vexs[k],G.arcs[k][j].adj};
}//for
}//MiniSpanTree
еБЗиЃЊзљСдЄ≠жЬЙnдЄ™й°ґзВєпЉМеИЩзђђдЄАдЄ™ињЫи°МеИЭеІЛеМЦзЪДеЊ™зОѓиѓ≠еП•зЪДйҐСеЇ¶дЄЇnпЉМзђђдЇМдЄ™еЊ™зОѓиѓ≠еП•зЪДйҐСеЇ¶дЄЇn-1гАВеЕґдЄ≠жЬЙдЄ§дЄ™еЖЕеЊ™зОѓпЉЪеЕґдЄАжШѓеЬ®closedge[v].lowcostдЄ≠ж±ВжЬАе∞ПеАЉпЉМеЕґйҐСеЇ¶дЄЇn-1пЉЫеЕґдЇМжШѓйЗНжЦ∞йАЙжЛ©еЕЈжЬЙжЬАе∞Пдї£дїЈзЪДиЊєпЉМеЕґйҐСеЇ¶дЄЇnгАВ зФ±ж≠§пЉМжЩЃйЗМеІЖзЃЧж≥ХзЪДжЧґйЧіе§НжЭВеЇ¶дЄЇO(n2)пЉМдЄОзљСдЄ≠зЪДиЊєжХ∞жЧ†еЕ≥пЉМеЫ†ж≠§йАВзФ®дЇОж±В茺箆еѓЖзЪДзљСзЪДжЬАе∞ПзФЯжИРж†СгАВ
2.еЕЛй≤БжЦѓеН°е∞ФпЉИKruskalпЉЙ :зФ±зВєеИ∞зЇњпЉМйАВеРИиЊєз®АзЦПзЪДзљСгАВжЧґйЧіе§НжЭВеЇ¶пЉЪO(e * loge)
Kruskal зЃЧж≥ХжШѓдЄАзІНжМЙзЕІзљСдЄ≠иЊєзЪДжЭГеАЉйАТеҐЮзЪДй°ЇеЇПжЮДйА†жЬАе∞ПзФЯжИРж†СзЪДжЦєж≥ХгАВ
еЯЇжЬђжАЭжГ≥жШѓпЉЪ
1) иЃЊжЧ†еРСињЮйАЪзљСдЄЇGпЉЭпЉИVпЉМEпЉЙпЉМдї§G зЪДжЬАе∞ПзФЯжИРж†СдЄЇTпЉМеЕґеИЭжАБдЄЇTпЉЭпЉИVпЉМ{}пЉЙпЉМеН≥еЉАеІЛжЧґпЉМжЬАе∞ПзФЯжИРж†СT зФ±еЫЊG дЄ≠зЪДn дЄ™й°ґзВєжЮДжИРпЉМй°ґзВєдєЛйЧіж≤°жЬЙдЄАжЭ°иЊєпЉМињЩж†ЈT дЄ≠еРДй°ґзВєеРДиЗ™жЮДжИРдЄАдЄ™ињЮйАЪеИЖйЗПгАВ
2) еЬ®EдЄ≠йАЙжЛ©дї£дїЈжЬАе∞ПзЪДиЊєпЉМиЛ•иѓ•иЊєдЊЭйЩДзЪДй°ґзВєиРљеЬ®TдЄ≠дЄНеРМзЪДињЮйАЪеИЖйЗПпЉМеИЩе∞Жж≠§иЊєеК†еЕ•еИ∞TдЄ≠пЉМеР¶еИЩиИНеЉГж≠§иЊєиАМйАЙжЛ©дЄЛдЄАжЭ°иЊєпЉИиЛ•иѓ•иЊєдЊЭйЩДзЪДдЄ§дЄ™й°ґзВєе±ЮдЇОеРМдЄАдЄ™ињЮйАЪеИЖйЗПпЉМеИЩиИНеОїж≠§иЊєпЉМдї•еЕНйА†жИРеЫЮиЈѓпЉЙгАВдЊЭж≠§з±їжО®пЉМељУT дЄ≠зЪДињЮйАЪеИЖйЗПдЄ™жХ∞дЄЇ1 жЧґпЉМж≠§ињЮйАЪеИЖйЗПдЊњдЄЇG зЪДдЄАж£µжЬАе∞ПзФЯжИРж†СгАВ
жМЙзЕІKruskal жЦєж≥ХжЮДйА†жЬАе∞ПзФЯжИРж†СзЪДињЗз®Ле¶ВеЫЊжЙАз§ЇпЉЪ
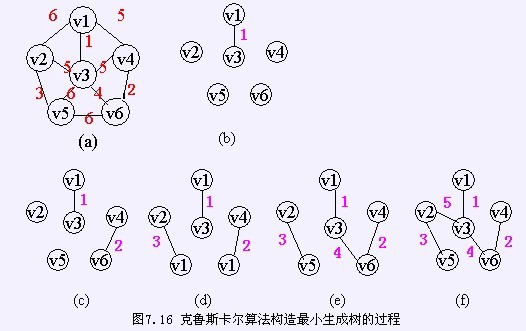
еЬ®жЮДйА†ињЗз®ЛдЄ≠пЉМжМЙзЕІзљСдЄ≠иЊєзЪДжЭГеАЉзФ±е∞ПеИ∞е§ІзЪДй°ЇеЇПпЉМдЄНжЦ≠йАЙеПЦељУеЙНжܙ襀йАЙеПЦзЪДиЊєйЫЖдЄ≠жЭГеАЉжЬАе∞ПзЪДиЊєгАВдЊЭжНЃзФЯжИРж†СзЪДж¶ВењµпЉМn дЄ™зїУзВєзЪДзФЯжИРж†СпЉМжЬЙnпЉН1 жЭ°иЊєпЉМжХЕеПНе§НдЄКињ∞ињЗз®ЛпЉМзЫіеИ∞йАЙеПЦдЇЖnпЉН1 жЭ°иЊєдЄЇж≠ҐпЉМе∞±жЮДжИРдЇЖдЄАж£µжЬАе∞ПзФЯжИРж†СгАВ
Kruskal зЃЧж≥ХзЪДеЃЮзО∞пЉЪ
зЃЧж≥ХзЪДж°ЖжЮґпЉЪ
жЮДйА†йЭЮињЮйАЪеЫЊTпЉЭпЉИVпЉМ{}пЉЙ
k = i= 0пЉЫ//kдЄЇиЊєжХ∞
whileпЉИkгАК< n-1пЉЙ {
i++;
ж£АжЯ•иЊєEдЄ≠зђђiжЭ°иЊєзЪДжЭГеАЉ
жЬАе∞ПиЊєпЉИuпЉМvпЉЙ
иЛ•пЉИuпЉМvпЉЙ еК†еЕ•TдЄНжШѓTдЇІзФЯеЫЮиЈѓпЉМ
еИЩпЉИuпЉМvпЉЙеК†еЕ•TпЉМдЄФk++
}
cиѓ≠и®АеЃЮзО∞пЉЪ
C иѓ≠и®АеЃЮзО∞Kruskal зЃЧж≥ХпЉМеЕґдЄ≠еЗљжХ∞Find зЪДдљЬзФ®жШѓеѓїжЙЊеЫЊдЄ≠й°ґзВєжЙАеЬ®ж†СзЪДж†єзїУзВєеЬ®жХ∞зїДfather дЄ≠зЪДеЇПеПЈгАВйЬАиѓіжШОзЪДжШѓпЉМеЬ®з®ЛеЇПдЄ≠е∞Жй°ґзВєзЪДжХ∞жНЃз±їеЮЛеЃЪдєЙжИРжХіеЮЛпЉМиАМеЬ®еЃЮйЩЕеЇФзФ®дЄ≠пЉМеПѓдЊЭжНЃеЃЮйЩЕйЬАи¶БжЭ•иЃЊеЃЪгАВ
typedef int elemtype;
typedef struct {
elemtype v1;
elemtype v2;
int cost;
}EdgeType;
void KruskalпЉИEdgeType edges[ ]пЉМint nпЉЙ
/*зФ®Kruskal жЦєж≥ХжЮДйА†жЬЙn дЄ™й°ґзВєзЪДеЫЊedges зЪДжЬАе∞ПзФЯжИРж†С*/
{ int father[MAXEDGE];
int i,j,vf1,vf2;
for (i=0;i<n;i++) father[i]=-1;
i=0;j=0;
while(i<MAXEDGE && j<n-1)
{ vf1=Find(father,edges[i].v1);
vf2=Find(father,edges[i].v2);
if (vf1!=vf2)
{ father[vf2]=vf1;
j++;
printf(вАЬ%3d%3d\nвАЭ,edges[i].v1,edges[i].v2);
}
i++;
}
}
//find еЗљжХ∞
int FindпЉИint father[ ]пЉМint vпЉЙ
/*еѓїжЙЊй°ґзВєv жЙАеЬ®ж†СзЪДж†єзїУзВє*/
{ int t;
t=v;
while(father[t]>=0)
t=father[t];
return(t);
}
2. AOVзљСдЄОжЛУжЙСжОТеЇП
2.1пЉОAOVзљС(Activity on vertex network)
жЙАжЬЙзЪДеЈ•з®ЛжИЦиАЕжЯРзІНжµБз®ЛеПѓдї•еИЖдЄЇиЛ•еє≤дЄ™е∞ПзЪДеЈ•з®ЛжИЦйШґжЃµпЉМињЩдЇЫе∞ПзЪДеЈ•з®ЛжИЦйШґжЃµе∞±зІ∞дЄЇжіїеК®гАВиЛ•дї•еЫЊдЄ≠зЪДй°ґзВєжЭ•и°®з§ЇжіїеК®пЉМжЬЙеРСиЊєпЉИеЉІпЉЙи°®з§ЇжіїеК®дєЛйЧізЪДдЉШеЕИеЕ≥з≥їпЉМеИЩињЩж†ЈжіїеК®еЬ®й°ґзВєдЄКзЪДжЬЙеРСеЫЊзІ∞дЄЇAOV зљСпЉИActivity On Vertex NetworkпЉЙгАВеЬ®AOV зљСдЄ≠пЉМиЛ•дїОй°ґзВєiеИ∞й°ґзВєjдєЛйЧіе≠ШеЬ®дЄАжЭ°жЬЙеРСиЈѓеЊДпЉМзІ∞й°ґзВєiжШѓй°ґзВєjзЪДеЙНй©±пЉМжИЦиАЕзІ∞й°ґзВєj жШѓй°ґзВєiзЪДеРОзїІгАВиЛ•<i,j>жШѓеЫЊдЄ≠зЪДеЉІпЉМеИЩзІ∞й°ґзВєiжШѓй°ґзВєj зЪДзЫіжО•еЙНй©±пЉМй°ґзВєj жШѓй°ґзВєi зЪДзЫіжО•еРОй©±гАВ
AOV зљСдЄ≠зЪДеЉІи°®з§ЇдЇЖжіїеК®дєЛйЧіе≠ШеЬ®зЪДеИґзЇ¶еЕ≥з≥їгАВдЊЛе¶ВпЉМиЃ°зЃЧжЬЇдЄУдЄЪзЪДе≠¶зФЯењЕй°їеЃМжИРдЄАз≥їеИЧиІДеЃЪзЪДеЯЇз°АиѓЊеТМдЄУдЄЪиѓЊжЙНиГљжѓХдЄЪгАВе≠¶зФЯжМЙзЕІжАОж†ЈзЪДй°ЇеЇПжЭ•е≠¶дє†ињЩдЇЫиѓЊз®ЛеСҐпЉЯињЩдЄ™йЧЃйҐШеσ俕襀зЬЛжИРжШѓдЄАдЄ™е§ІзЪДеЈ•з®ЛпЉМеЕґжіїеК®е∞±жШѓе≠¶дє†жѓПдЄАйЧ®иѓЊз®ЛгАВињЩдЇЫиѓЊз®ЛзЪДеРНзІ∞дЄОзЫЄеЇФдї£еПЈе¶Ви°®жЙАз§ЇгАВ
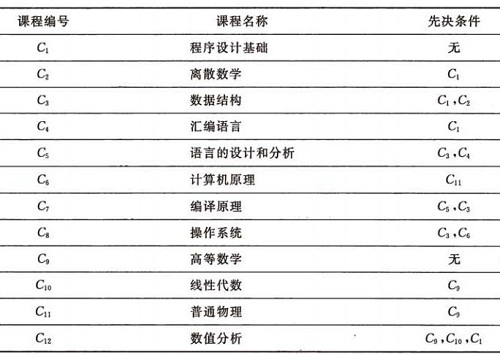
иѓЊз®ЛдєЛйЧізЪДдЉШеЕИеЕ≥з≥їеЫЊпЉЪ

иѓ•еЫЊзЪДжЛУжЙСжЬЙеЇПз≥їеИЧпЉЪ

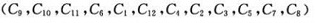
ж≥®жДПпЉЪ
еЬ®AOV-зљСдЄ≠дЄНеЇФиѓ•еЗЇзО∞жЬЙеРСзОѓпЉМеЫ†дЄЇе≠ШеЬ®зОѓжДПеС≥зЭАжЯРй°єжіїеК®еЇФдї•иЗ™еЈ±дЄЇеЕИеЖ≥жЭ°дїґгАВиЛ•иЃЊиЃ°еЗЇињЩж†ЈзЪДжµБз®ЛеЫЊпЉМеЈ•з®ЛдЊњжЧ†ж≥ХињЫи°МгАВиАМеѓєз®ЛеЇПзЪДжХ∞жНЃжµБеЫЊжЭ•иѓіпЉМеИЩи°®жШОе≠ШеЬ®дЄАдЄ™ж≠їеЊ™зОѓгАВеЫ†ж≠§пЉМеѓєзїЩеЃЪзЪДAOV-зљСеЇФй¶ЦеЕИеИ§еЃЪзљСдЄ≠жШѓеР¶е≠ШеЬ®зОѓгАВж£АжµЛзЪДеКЮж≥ХжШѓеѓєжЬЙеРСеЫЊжЮДйА†еЕґй°ґзВєзЪДжЛУжЙСжЬЙеЇПеЇПеИЧпЉМиЛ•зљСдЄ≠жЙАжЬЙй°ґзВєйГљеЬ®еЃГзЪДжЛУжЙСжЬЙеЇПеЇПеИЧдЄ≠пЉМеИЩиѓ•AOV-зљСдЄ≠ењЕеЃЪдЄНе≠ШеЬ®зОѓгАВ
2.2пЉОжЛУжЙСжОТеЇП
з¶їжХ£жХ∞е≠¶еЯЇз°АзЯ•иѓЖпЉЪ
й¶ЦеЕИе§Ндє†дЄАдЄЛз¶їжХ£жХ∞е≠¶дЄ≠зЪДеБПеЇПйЫЖеРИдЄОеЕ®еЇПйЫЖеРИдЄ§дЄ™ж¶ВењµгАВ
иЛ•йЫЖеРИA дЄ≠зЪДдЇМеЕГеЕ≥з≥їR жШѓиЗ™еПНзЪДгАБйЭЮеѓєзІ∞зЪДеТМдЉ†йАТзЪДпЉМеИЩR жШѓA дЄКзЪДеБПеЇПеЕ≥з≥їгАВйЫЖеРИA дЄОеЕ≥з≥їR дЄАиµЈзІ∞дЄЇдЄАдЄ™еБПеЇПйЫЖеРИгАВ
иЛ•R жШѓйЫЖеРИA дЄКзЪДдЄАдЄ™еБПеЇПеЕ≥з≥їпЉМе¶ВжЮЬеѓєжѓПдЄ™aгАБbвИИA ењЕжЬЙaRb жИЦbRa пЉМеИЩR жШѓAдЄКзЪДеЕ®еЇПеЕ≥з≥їгАВйЫЖеРИA дЄОеЕ≥з≥їR дЄАиµЈзІ∞дЄЇдЄАдЄ™еЕ®еЇПйЫЖеРИгАВ
зЫіиІВеЬ∞зЬЛпЉМеБПеЇПжМЗйЫЖеРИдЄ≠дїЕжЬЙйГ®еИЖжИРеСШдєЛйЧіеПѓжѓФиЊГпЉМиАМеЕ®еЇПжМЗйЫЖеРИдЄ≠еЕ®дљУжИРеСШдєЛйЧіеЭЗеПѓжѓФиЊГгАВ
[дЊЛе¶В]пЉМеЫЊ7.25жЙАз§ЇзЪДдЄ§дЄ™жЬЙеРСеЫЊпЉМеЫЊдЄ≠еЉІ(x,y)и°®з§ЇxвЙ§yпЉМеИЩ(a)и°®з§ЇеБПеЇПпЉМ(b)и°®з§ЇеЕ®еЇПгАВиЛ•еЬ®(a)зЪДжЬЙеРСеЫЊдЄКдЇЇдЄЇеЬ∞еК†дЄАдЄ™и°®з§Їv2вЙ§v3зЪДеЉІ(зђ¶еПЈвАЬвЙ§вАЭи°®з§Їv2йҐЖеЕИдЇОv3)пЉМеИЩ(a)и°®з§ЇзЪДдЇ¶дЄЇеЕ®еЇПпЉМдЄФињЩдЄ™еЕ®еЇПзІ∞дЄЇжЛУжЙСжЬЙеЇП(Topological Order)пЉМиАМзФ±еБПеЇПеЃЪдєЙеЊЧеИ∞жЛУжЙСжЬЙеЇПзЪДжУНдљЬдЊњжШѓжЛУжЙСжОТеЇПгАВ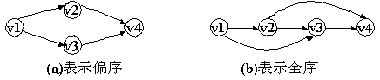
3.3 жЛУжЙСжОТеЇПзЃЧж≥Х
еѓєAOV зљСињЫи°МжЛУжЙСжОТеЇПзЪДжЦєж≥ХеТМж≠•й™§жШѓпЉЪ
1гАБдїОAOV зљСдЄ≠йАЙжЛ©дЄАдЄ™ж≤°жЬЙеЙНй©±зЪДй°ґзВєпЉИиѓ•й°ґзВєзЪДеЕ•еЇ¶дЄЇ0пЉЙеєґдЄФиЊУеЗЇеЃГпЉЫ
2гАБдїОзљСдЄ≠еИ†еОїиѓ•й°ґзВєпЉМеєґдЄФеИ†еОїдїОиѓ•й°ґзВєеПСеЗЇзЪДеЕ®йГ®жЬЙеРСиЊєпЉЫ
3гАБйЗНе§НдЄКињ∞дЄ§ж≠•пЉМзЫіеИ∞еЙ©дљЩзЪДзљСдЄ≠дЄНеЖНе≠ШеЬ®ж≤°жЬЙеЙНй©±зЪДй°ґзВєдЄЇж≠ҐгАВ
ињЩж†ЈжУНдљЬзЪДзїУжЮЬжЬЙдЄ§зІНпЉЪдЄАзІНжШѓзљСдЄ≠еЕ®йГ®й°ґзВєйÚ襀иЊУеЗЇпЉМињЩиѓіжШОзљСдЄ≠дЄНе≠ШеЬ®жЬЙеРСеЫЮиЈѓпЉЫеП¶дЄАзІНе∞±жШѓзљСдЄ≠й°ґзВєжܙ襀еЕ®йГ®иЊУеЗЇпЉМеЙ©дљЩзЪДй°ґзВєеЭЗдЄНеЙНй©±й°ґзВєпЉМињЩиѓіжШОзљСдЄ≠е≠ШеЬ®жЬЙеРСеЫЮиЈѓгАВ
дї•дЄЛеЫЊ(a)дЄ≠зЪДжЬЙеРСеЫЊдЄЇдЊЛпЉМеЫЊдЄ≠v1пЉМеТМv6ж≤°жЬЙеЙНй©±пЉМеИЩеПѓдїїйАЙдЄАдЄ™гАВеБЗиЃЊеЕИиЊУеЗЇv6, еЬ®еИ†йЩ§v6еПКеЉІ<v6пЉМv4>пЉМ<v6пЉМv5>дєЛеРОпЉМеП™жЬЙй°ґзВєv1ж≤°жЬЙеЙНй©±пЉМеИЩиЊУеЗЇvlдЄФеИ†еОїvlеПКеЉІ<v1пЉМv2>гАБ<v1пЉМv3>еТМ<v1, v4>пЉМдєЛеРОv3еТМv4йГљж≤°жЬЙеЙНй©±гАВдЊЭжђ°з±їжО®пЉМеПѓдїОдЄ≠дїїйАЙдЄАдЄ™зїІзї≠ињЫи°МгАВжЬАеРОеЊЧеИ∞иѓ•жЬЙеРСеЫЊзЪДжЛУжЙСжЬЙеЇПеЇПеИЧдЄЇпЉЪ
еЫЊAOV-зљСеПКеЕґжЛУжЙСжЬЙеЇПеЇПеИЧдЇІзФЯзЪДињЗз®Л
(a)AOV-зљСпЉЫ(b)иЊУеЗЇv6дєЛеРОпЉЫ(c)иЊУеЗЇv1дєЛеРОпЉЫ(d)иЊУеЗЇv4дєЛеРОпЉЫ(e)иЊУеЗЇv3дєЛеРОпЉЫ(f)иЊУеЗЇv2дєЛеРО
дЄЇдЇЖеЃЮзО∞дЄКињ∞зЃЧж≥ХпЉМеѓєAOV зљСйЗЗзФ®йВїжО•и°®е≠ШеВ®жЦєеЉПпЉМеєґдЄФйВїжО•и°®дЄ≠й°ґзВєзїУзВєдЄ≠еҐЮеК†дЄАдЄ™иЃ∞ељХй°ґзВєеЕ•еЇ¶зЪДжХ∞жНЃеЯЯпЉМеН≥й°ґзВєзїУжЮДиЃЊдЄЇпЉЪ

й°ґзВєи°®зїУзВєзїУжЮДзЪДжППињ∞жФєдЄЇпЉЪ
typedef struct vnode{ /*й°ґзВєи°®зїУзВє*/
int count /*е≠ШжФЊй°ґзВєеЕ•еЇ¶*/
VertexType vertex; /*й°ґзВєеЯЯ*/
EdgeNode * firstedge; /*иЊєи°®е§іжМЗйТИ*/
}VertexNode;
ељУзДґдєЯеПѓдї•дЄНеҐЮиЃЊеЕ•еЇ¶еЯЯпЉМиАМеП¶е§ЦиЃЊдЄАдЄ™дЄАзїіжХ∞зїДжЭ•е≠ШжФЊжѓПдЄАдЄ™зїУзВєзЪДеЕ•еЇ¶гАВзЃЧж≥ХдЄ≠еПѓиЃЊзљЃдЇЖдЄАдЄ™е†Жж†ИпЉМеЗ°жШѓзљСдЄ≠еЕ•еЇ¶дЄЇ0 зЪДй°ґзВєйГље∞ЖеЕґеЕ•ж†ИгАВдЄЇж≠§пЉМжЛУжЙСжОТеЇПзЪДзЃЧж≥Хж≠•й™§дЄЇпЉЪ
1гАБе∞Жж≤°жЬЙеЙНй©±зЪДй°ґзВєпЉИcount еЯЯдЄЇ0пЉЙеОЛеЕ•ж†ИпЉЫ
2гАБдїОж†ИдЄ≠йААеЗЇж†Ий°ґеЕГзі†иЊУеЗЇпЉМеєґжККиѓ•й°ґзВєеЉХеЗЇзЪДжЙАжЬЙжЬЙеРСиЊєеИ†еОїпЉМеН≥жККеЃГзЪДеРДдЄ™йВїжО•й°ґзВєзЪДеЕ•еЇ¶еЗП1пЉЫ
3гАБе∞ЖжЦ∞зЪДеЕ•еЇ¶дЄЇ0 зЪДй°ґзВєеЖНеЕ•е†Жж†ИпЉЫ
4гАБйЗНе§НвС°пљЮвС£пЉМзЫіеИ∞ж†ИдЄЇз©ЇдЄЇж≠ҐгАВж≠§жЧґжИЦиАЕжШѓеЈ≤зїПиЊУеЗЇеЕ®йГ®й°ґзВєпЉМжИЦиАЕеЙ©дЄЛзЪДй°ґзВєдЄ≠ж≤°жЬЙеЕ•еЇ¶дЄЇ0 зЪДй°ґзВєгАВ
дЄЇдЇЖйБњеЕНйЗНе§Нж£АжµЛеЕ•еЇ¶дЄЇйЫґзЪДй°ґзВєпЉМеПѓеП¶иЃЊдЄАж†ИжЪВе≠ШжЙАжЬЙеЕ•еЇ¶дЄЇйЫґзЪДй°ґзВєгАВ
Status Topological Sort(ALGraph G){
//жЬЙеРСеЫЊGйЗЗзФ®йВїжО•и°®е≠ШеВ®зїУжЮДгАВ
//иЛ•GжЧ†еЫЮиЈѓпЉМеИЩиЊУеЗЇGзЪДй°ґзВєзЪД1дЄ™жЛУжЙСеЇПеИЧеєґињФеЫЮOKпЉМеР¶еИЩERRORгАВ
FindInDegree(GпЉМindegree)пЉЫ //еѓєеРДй°ґзВєж±ВеЕ•еЇ¶indegree[0..vernum-1]
InitStack(S)пЉЫ
for(i=0пЉЫi<G.vexnumпЉЫ ++i)
if(!indegree[i])Push(SпЉМi) //еїЇйЫґеЕ•еЇ¶й°ґзВєж†И,sеЕ•еЇ¶дЄЇ0иАЕињЫж†И
count=0пЉЫ //еѓєиЊУеЗЇй°ґзВєиЃ°жХ∞
while (!StackEmpty(S)) {
Pop(SпЉМi)пЉЫ
printf(iпЉМG.vertices[i].data)пЉЫ ++countпЉЫ //иЊУеЗЇiеПЈй°ґзВєеєґиЃ°жХ∞
for(p=G.vertices[i].firstarcпЉЫpпЉЫ p=pвАФ>nextarc) {
k=pвАФ>adivexпЉЫ //еѓєiеПЈй°ґзВєзЪДжѓПдЄ™йВїжО•зВєзЪДеЕ•еЇ¶еЗП1
if(пЉБ(--indegree[k]))Push(SпЉМk)пЉЫ//иЛ•еЕ•еЇ¶еЗПдЄЇ0пЉМеИЩеЕ•ж†И
}//for
}//while
if(count<G.vexnum) return ERRORпЉЫ //иѓ•жЬЙеРСеЫЊжЬЙеЫЮиЈѓ
else return OKпЉЫ
}//TopologicalSort
3. еЕ≥йФЃиЈѓеЊД(AOEзљС)
3.1AOEзљСпЉЪпЉИActivity on edge networkпЉЙ
AOEзљСз§ЇжДПеЫЊиЛ•еЬ®еЄ¶жЭГзЪДжЬЙеРСеЫЊдЄ≠пЉМдї•й°ґзВєи°®з§ЇдЇЛдїґпЉМдї•жЬЙеРСиЊєи°®з§ЇжіїеК®пЉМиЊєдЄКзЪДжЭГеАЉи°®з§ЇжіїеК®зЪДеЉАйФАпЉИе¶Виѓ•жіїеК®жМБзї≠зЪДжЧґйЧіпЉЙпЉМеИЩж≠§еЄ¶жЭГзЪДжЬЙеРСеЫЊзІ∞дЄЇAOEзљСгАВ
3.2 еЃЮйЩЕйЧЃйҐШпЉЪ
е¶ВжЮЬзФ®AOEзљСжЭ•и°®з§ЇдЄАй°єеЈ•з®ЛпЉМйВ£дєИпЉМдїЕдїЕиАГиЩСеРДдЄ™е≠РеЈ•з®ЛдєЛйЧізЪДдЉШеЕИеЕ≥з≥їињШдЄНе§ЯпЉМжЫіе§ЪзЪДжШѓеЕ≥ењГжХідЄ™еЈ•з®ЛеЃМжИРзЪДжЬАзЯ≠жЧґйЧіжШѓе§Ъе∞СпЉЫеУ™дЇЫжіїеК®зЪДеїґжЬЯе∞ЖдЉЪељ±еУНжХідЄ™еЈ•з®ЛзЪДињЫеЇ¶пЉМиАМеК†йАЯињЩдЇЫжіїеК®жШѓеР¶дЉЪжПРйЂШжХідЄ™еЈ•з®ЛзЪДжХИзОЗгАВеЫ†ж≠§пЉМйАЪеЄЄеЬ®AOEзљСдЄ≠еИЧеЗЇеЃМжИРйҐДеЃЪеЈ•з®ЛиЃ°еИТжЙАйЬАи¶БињЫи°МзЪДжіїеК®пЉМжѓПдЄ™жіїеК®иЃ°еИТеЃМжИРзЪДжЧґйЧіпЉМи¶БеПСзФЯеУ™дЇЫдЇЛдїґдї•еПКињЩдЇЫдЇЛдїґдЄОжіїеК®дєЛйЧізЪДеЕ≥з≥їпЉМдїОиАМеПѓдї•з°ЃеЃЪиѓ•й°єеЈ•з®ЛжШѓеР¶еПѓи°МпЉМдЉ∞зЃЧеЈ•з®ЛеЃМжИРзЪДжЧґйЧідї•еПКз°ЃеЃЪеУ™дЇЫжіїеК®жШѓељ±еУНеЈ•з®ЛињЫеЇ¶зЪДеЕ≥йФЃгАВ
е¶ВеЫЊжШѓдЄАдЄ™еБЗжГ≥зЪДжЬЙ11й°єжіїеК®зЪДAOE-зљСпЉЪ
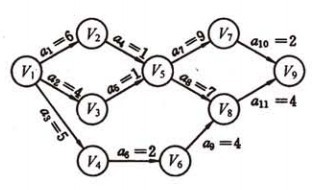
еЕґдЄ≠жЬЙ9дЄ™дЇЛдїґv1пЉМv2пЉМv3пЉМвА¶пЉМv9пЉМжѓПдЄ™дЇЛдїґи°®з§ЇеЬ®еЃГдєЛеЙНзЪДжіїеК®еЈ≤зїПеЃМжИРпЉМеЬ®еЃГдєЛеРОзЪДжіїеК®еПѓдї•еЉАеІЛгАВе¶Вv1и°®з§ЇжХідЄ™еЈ•з®ЛеЉАеІЛпЉМv9и°®з§ЇжХідЄ™еЈ•з®ЛзїУжЭЯпЉМv5и°®з§Їa4еТМa5еЈ≤зїПеЃМжИРпЉМa7еТМa8еПѓдї•еЉАеІЛгАВдЄОжѓПдЄ™жіїеК®зЫЄиБФз≥їзЪДжХ∞жШѓжЙІи°Миѓ•жіїеК®жЙАйЬАзЪДжЧґйЧігАВжѓФе¶ВпЉМжіїеК®a1йЬАи¶Б6姩пЉМa2йЬАи¶Б4姩з≠ЙгАВ
еТМAOV-зљСдЄНеРМпЉМеѓєAOE-зљСжЬЙеЊЕз†Фз©ґзЪДйЧЃйҐШжШѓпЉЪ
(1)еЃМжИРжХій°єеЈ•з®ЛиЗ≥е∞СйЬАи¶Бе§Ъе∞СжЧґйЧі?
(2)еУ™дЇЫжіїеК®жШѓељ±еУНеЈ•з®ЛињЫеЇ¶зЪДеЕ≥йФЃ?
3.3 еЕ≥йФЃиЈѓеЊД
зФ±дЇОеЬ®AOE-зљСдЄ≠жЬЙдЇЫжіїеК®еПѓдї•еєґи°МеЬ∞ињЫи°МпЉМжЙАдї•еЃМжИРеЈ•з®ЛзЪДжЬАзЯ≠жЧґйЧіжШѓдїОеЉАеІЛзВєеИ∞еЃМжИРзВєзЪДжЬАйХњиЈѓеЊДзЪДйХњеЇ¶(ињЩйЗМжЙАиѓізЪДиЈѓеЊДйХњеЇ¶жШѓжМЗиЈѓеЊДдЄКеРДжіїеК®жМБзї≠жЧґйЧідєЛеТМпЉМдЄНжШѓиЈѓеЊДдЄКеЉІзЪДжХ∞зЫЃ)гАВиЈѓеЊДйХњеЇ¶жЬАйХњзЪДиЈѓеЊДеПЂеБЪеЕ≥йФЃиЈѓеЊД(Critical Path)гАВ
AOEзљСжЬЙеЕ≥зЪДж¶ВењµпЉЪ
1)иЈѓеЊДйХњеЇ¶пЉЪиЈѓеЊДдЄКеРДдЄ™жіїеК®зЪДжМБзї≠жЧґйЧідєЛеТМ
2)еЃМжИРеЈ•з®ЛзЪДжЬАзЯ≠жЧґйЧіпЉЪзФ±дЇОAOEзљСдЄ≠жЬЙжіїеК®жШѓеєґи°МињЫи°МзЪДпЉМжЙАдї•еЃМжИРеЈ•з®ЛзЪДжЬАзЯ≠жЧґйЧіе∞±жШѓдїОеЉАеІЛзВєеИ∞еЃМжИРзВєзЪДжЬАйХњиЈѓеК≤йХњеЇ¶гАВ
3)жіїеК®жЬАжЧ©еЉАеІЛжЧґйЧі(earlist time)(e(i))пЉЪдїОеЉАеІЛзВєеИ∞й°ґзВєviзЪДжЬАйХњиЈѓеЊДзІ∞дЄЇдЇЛдїґviзЪДжЬАжЧ©еПСзФЯжЧґйЧігАВињЩдЄ™жЧґйЧіеЖ≥еЃЪдЇЖдї•viдЄЇе∞ЊзЪДеЉІи°®з§ЇзЪДжіїеК®зЪДжЬАжЧ©еЉАеІЛжЧґйЧі.
4)жіїеК®жЬАжЩЪеЉАеІЛжЧґйЧі(latest time)(l(i))пЉЪеЬ®дЄНжО®ињЯжХідЄ™еЈ•з®ЛеЃМжИРзЪДеЙНжПРдЄЛпЉМжіїеК®жЬАињЯеЉАеІЛзЪДжЧґйЧі
5)еЃМжИРжіїеК®зЪДжЧґйЧідљЩйЗПпЉЪиѓ•жіїеК®зЪДжЬАињЯеЉАеІЛжЧґйЧіеЗПеОїжЬАжЧ©еЉАеІЛжЧґйЧі
6)еЕ≥йФЃиЈѓеЊД(critical path)пЉЪиЈѓеЊДйХњеЇ¶жЬАйХњзЪДиЈѓеЊДзІ∞дЄЇеЕ≥йФЃиЈѓеЊД
7)еЕ≥йФЃжіїеК®(critical activity):еЕ≥йФЃиЈѓеЊДдЄКзЪДжіїеК®зІ∞дЄЇеЕ≥йФЃжіїеК®пЉМеЕ≥йФЃжіїеК®зЪДзЙєзВєжШѓ:e(i)=l(i)еИЖжЮРеЕ≥йФЃиЈѓеЊДзЪДзЫЃзЪДе∞±жШѓиЊ®еИЂеЬ®жХідЄ™еЈ•з®ЛдЄ≠еУ™дЇЫжШѓеЕ≥йФЃжіїеК®пЉМдї•дЊњдЇЙеПЦжПРйЂШеЕ≥йФЃжіїеК®зЪДеЈ•дљЬжХИзОЗпЉМзЉ©зЯ≠жХідЄ™еЈ•з®ЛзЪДеЈ•жЬЯгАВ
3.4 иІ£еЖ≥жЦєж°ИпЉЪ
зФ±дЄКеИЖжЮРеПѓзЯ•пЉМиЊ®еИЂеЕ≥йФЃжіїеК®е∞±жШѓи¶БжЙЊe(i)=l(i)зЪДжіїеК®гАВдЄЇдЇЖж±ВеЊЧAOE-зљСдЄ≠жіїеК®зЪДe(i)еТМl(i)пЉМ й¶ЦеЕИж±ВдЇЛдїґзЪДжЬАжЧ©еПСзФЯжЧґйЧіve(j)еТМжЬАињЯеПСзФЯжЧґйЧіvl(j)гАВе¶ВжЮЬжіїеК®aiзФ±еЉІ<j,k>и°®з§ЇпЉМеЕґжМБзї≠жЧґйЧіиЃ∞дЄЇdut(<j,k>),еИЩжЬЙе¶ВдЄЛеЕ≥з≥їпЉЪ
e(i ) = ve(j)
l(i) = vl(k)-dut(<j,k>)
ж±Вve(j)еТМvl(j)йЬАеИЖдЄ§ж≠•ињЫи°МпЉЪ
пЉИ1пЉЙдїОve(0)еЉАеІЛеРСеЙНйАТжО®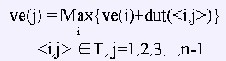
еЕґдЄ≠пЉМTжШѓжЙАжЬЙдї•зђђjдЄ™й°ґзВєдЄЇе§ізЪДеЉІзЪДзїУеРИгАВ
пЉИ2пЉЙдїОvl(n-1)=ve(n-1)иµЈеРСеРОйАТжО®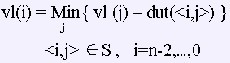
еЕґдЄ≠пЉМSжШѓжЙАжЬЙдї•зђђiдЄ™й°ґзВєдЄЇе∞ЊзЪДеЉІзЪДйЫЖеРИгАВ
ињЩдЄ§дЄ™йАТжО®еЕђеЉПзЪДиЃ°зЃЧењЕй°їеИЖеИЂеЬ®жЛУжЙСжЬЙеЇПеТМйАЖжЛУжЙСжЬЙеЇПзЪДеЙНжПРдЄЛињЫи°МгАВдєЯе∞±жШѓиѓіve(j-1)ењЕй°їеЬ®vjзЪДжЙАжЬЙеЙНй©±зЪДжЬАжЧ©еПСзФЯжЧґйЧіж±ВеЊЧдєЛеРОжЙНиГљз°ЃеЃЪпЉМиАМvl(j-1)еИЩењЕй°їеЬ®vjзЪДжЙАжЬЙеРОзїІзЪДжЬАињЯеПСзФЯжЧґйЧіж±ВеЊЧдєЛеРОжЙНиГљз°ЃеЃЪгАВеЫ†ж≠§пЉМеПѓдї•еЬ®жЛУжЙСжОТеЇПзЪДеЯЇз°АдЄКиЃ°зЃЧve(j-1)еТМvl(j-1)гАВ
3.5 еЕ≥йФЃиЈѓеЊДзЪДзЃЧж≥ХпЉЪ
(1)иЊУеЕ•eжЭ°еЉІ<jпЉМk>пЉМеїЇзЂЛAOE-зљСзЪДе≠ШеВ®зїУжЮДпЉЫ
(2)дїОжЇРзВєv0еЗЇеПСпЉМдї§ve[0]=0пЉМжМЙжЛУжЙСжЬЙеЇПж±ВеЕґдљЩеРДй°ґзВєзЪДжЬАжЧ©еПСзФЯжЧґйЧіve[i] (1вЙ§iвЙ§n-1)гАВе¶ВжЮЬеЊЧеИ∞зЪДжЛУжЙСжЬЙеЇПеЇПеИЧдЄ≠й°ґзВєдЄ™жХ∞е∞ПдЇОзљСдЄ≠й°ґзВєжХ∞nпЉМеИЩиѓіжШОзљСдЄ≠е≠ШеЬ®зОѓпЉМдЄНиГљж±ВеЕ≥йФЃиЈѓеЊДпЉМзЃЧж≥ХзїИж≠ҐпЉЫеР¶еИЩжЙІи°Мж≠•й™§(3)гАВ
(3)дїОж±ЗзВєvnеЗЇеПСпЉМдї§vl[n-1]=ve[n-1]пЉМжМЙйАЖжЛУжЙСжЬЙеЇПж±ВеЕґдљЩеРДй°ґзВєзЪДжЬАињЯеПСзФЯжЧґйЧіvl[i](n-2вЙ•iвЙ•0)пЉЫ
(4)ж†єжНЃеРДй°ґзВєзЪДveеТМvlеАЉпЉМж±ВжѓПжЭ°еЉІsзЪДжЬАжЧ©еЉАеІЛжЧґйЧіe(s)еТМжЬАињЯеЉАеІЛжЧґйЧі l(s)гАВиЛ•жЯРжЭ°еЉІжї°иґ≥жЭ°дїґe(s)=l(s)пЉМеИЩдЄЇеЕ≥йФЃжіїеК®гАВ
еЕИе∞ЖжЛУжЙСжОТеЇПзЃЧж≥ХпЉЪTopologicalOrderпЉИпЉЙ
CriticalPathдЊњдЄЇж±ВеЕ≥йФЃиЈѓеЊДзЪДзЃЧж≥ХпЉЪ
Status TopologicalOrder(ALGraph GпЉМStack &T){
//жЬЙеРСзљСGйЗЗзФ®йВїжО•и°®е≠ШеВ®зїУжЮДпЉМж±ВеРДй°ґзВєдЇЛдїґзЪДжЬАжЧ©еПСзФЯжЧґйЧіve(еЕ®е±АеПШйЗП)гАВ
//TдЄЇжЛУжЙСеЇПеИЧй°ґзВєж†ИпЉМsдЄЇйЫґеЕ•еЇ¶й°ґзВєж†ИгАВиЛ•GжЧ†еЫЮиЈѓпЉМињФеЫЮGзЪДдЄАжЛУжЙСеЇПеИЧпЉМеЗљжХ∞еАЉдЄЇOKпЉМеР¶еИЩERRORгАВ
FindInDegree(GпЉМindegree)пЉЫ//еѓєеРДй°ґзВєж±ВеЕ•еЇ¶indegree[0..vernum-1]
for(i=0пЉЫi<G.vexnumпЉЫ ++i)
if(!indegree[i])Push(SпЉМi) //еїЇйЫґеЕ•еЇ¶й°ґзВєж†И,sеЕ•еЇ¶дЄЇ0иАЕињЫж†И
InitStack(T)пЉЫ count=0пЉЫve[0..G.vexnum-1]=0пЉЫ //еИЭеІЛеМЦ
while(!StackEmpty(S)){ //jеПЈй°ґзВєеЕ•Tж†ИеєґиЃ°жХ∞
Pop(SпЉМj)пЉЫ Push(TпЉМj)пЉЫ++count;
for(p=G.vertices[j].firstarcпЉЫpпЉЫp=p->nextarc){
k=pвАФ>adjvexпЉЫ //еѓєiеПЈй°ґзВєзЪДжѓПдЄ™йВїжО•зВєзЪДеЕ•еЇ¶еЗПl
if(--indegree[k]==0)Push(SпЉМk)пЉЫ //иЛ•еЕ•еЇ¶еЗПдЄЇ0пЉМеИЩеЕ•ж†И
if(ve[j]+*(p->info)>ve[k] ) ve[k]=ve[j]+*(p->info)пЉЫ
}//for *(p->info)=dut(<j,k>)
}//while
if(count<G.vexnum) return ERRORпЉЫ //иѓ•жЬЙеРСзљСжЬЙеЫЮиЈѓ
else return OKпЉЫ
}//TopologicalOrder
Status CriticalPath (ALGraph G){ //GдЄЇжЬЙеРСзљСпЉМиЊУеЗЇGзЪДеРДй°єеЕ≥йФЃжіїеК®гАВ
if(!TopologicalOrder(GпЉМT)) return ERRORпЉЫ //еИЭеІЛеМЦй°ґзВєдЇЛдїґзЪДжЬАињЯеПСзФЯжЧґйЧі
vl[0..G.vexnum-1]=ve[0..C.vexnum-1]пЉЫ //жМЙжЛУжЙСйАЖеЇПж±ВеРДй°ґзВєзЪДvlеАЉ
while(!StackEmpty(T))
for( Pop(T, j), p=G.vertices[j].firstarcпЉЫpпЉЫ p=p->nextarc){
k=p->adjvexпЉЫ dut=*(pвАФ>info)пЉЫ //dut<iпЉМk>
if(vl[k]-dut<vl[j]) vl[j]=vl[k]-dutпЉЫ }//for
for(j=0пЉЫj<G.vexnumпЉЫ++j) //ж±ВeeпЉМelеТМеЕ≥йФЃжіїеК®
for(p=G.vertices[j]пЉЫpпЉЫp=p->nextarc){
k=p->adjvexпЉЫ dut=*(pвАФ>info)пЉЫee=ve[j]пЉЫel=v1[k]-dutпЉЫtag = (ee==e1) ? вАШ*вАЩ пЉЪ вАШвАЩпЉЫ
printf(jпЉМkпЉМdutпЉМeeпЉМelпЉМtag)пЉЫ //иЊУеЗЇеЕ≥йФЃжіїеК®
}
}//CriticalPath
еЫЊ(a)жЙАз§ЇзљСзЪДеЕ≥йФЃиЈѓеЊДпЉЪеПѓиІБa2гАБa5еТМa7дЄЇеЕ≥йФЃжіїеК®пЉМзїДжИРдЄАжЭ°дїОжЇРзВєеИ∞ж±ЗзВєзЪДеЕ≥йФЃиЈѓеЊДпЉМе¶ВеЫЊ(b)жЙАз§ЇгАВ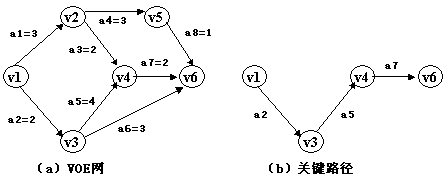
еЫЊ(a)жЙАз§ЇзљСзЪДиЃ°зЃЧзїУжЮЬ:

4. жЬАзЯ≠иЈѓеЊД
жЬАзЯ≠иЈѓеЊДйЧЃйҐШжШѓеЫЊзЪДеПИдЄАдЄ™жѓФиЊГеЕЄеЮЛзЪДеЇФзФ®йЧЃйҐШгАВдЊЛе¶ВпЉМжЯРдЄАеЬ∞еМЇзЪДдЄАдЄ™еЕђиЈѓзљСпЉМзїЩеЃЪдЇЖиѓ•зљСеЖЕзЪДn дЄ™еЯОеЄВдї•еПКињЩдЇЫеЯОеЄВдєЛйЧізЪДзЫЄйАЪеЕђиЈѓзЪДиЈЭз¶їпЉМиГљеР¶жЙЊеИ∞еЯОеЄВA еИ∞еЯОеЄВB дєЛйЧідЄАжЭ°дЄЊдЊЛжЬАињСзЪДйАЪиЈѓеСҐпЉЯ
е¶ВжЮЬе∞ЖеЯОеЄВзФ®зВєи°®з§ЇпЉМеЯОеЄВйЧізЪДеЕђиЈѓзФ®иЊєи°®з§ЇпЉМеЕђиЈѓзЪДйХњеЇ¶дљЬдЄЇиЊєзЪДжЭГеАЉпЉМйВ£дєИпЉМињЩдЄ™йЧЃйҐШе∞±еПѓељТзїУдЄЇеЬ®зљСеЫЊдЄ≠пЉМж±ВзВєA еИ∞зВєB зЪДжЙАжЬЙиЈѓеЊДдЄ≠пЉМиЊєзЪДжЭГеАЉдєЛеТМжЬАзЯ≠зЪДйВ£дЄАжЭ°иЈѓеЊДгАВињЩжЭ°иЈѓеЊДе∞±жШѓдЄ§зВєдєЛйЧізЪДжЬАзЯ≠иЈѓеЊДпЉМеєґзІ∞иЈѓеЊДдЄКзЪДзђђдЄАдЄ™й°ґзВєдЄЇжЇРзВєпЉИSourseпЉЙпЉМжЬАеРОдЄАдЄ™й°ґзВєдЄЇзїИзВєпЉИDestinationпЉЙгАВ
еНХжЇРзВєзЪДжЬАзЯ≠иЈѓеЊДйЧЃйҐШпЉЪзїЩеЃЪеЄ¶жЭГжЬЙеРСеЫЊGпЉЭпЉИVпЉМEпЉЙеТМжЇРзВєvвИИVпЉМж±ВдїОv еИ∞G дЄ≠еЕґдљЩеРДй°ґзВєзЪДжЬАзЯ≠иЈѓеЊДгАВеЬ®дЄЛйЭҐзЪДиЃ®иЃЇдЄ≠еБЗиЃЊжЇРзВєдЄЇv0гАВ
иІ£еЖ≥йЧЃйҐШзЪДињ™жЭ∞жЦѓзЙєжЛЙзЃЧж≥ХпЉЪ
еН≥зФ±ињ™жЭ∞жЦѓзЙєжЛЙпЉИDijkstraпЉЙжПРеЗЇзЪДдЄАдЄ™жМЙиЈѓеЊДйХњеЇ¶йАТеҐЮзЪДжђ°еЇПдЇІзФЯжЬАзЯ≠иЈѓеЊДзЪДзЃЧж≥ХгАВй¶ЦеЕИж±ВеЗЇйХњеЇ¶жЬАзЯ≠зЪДдЄАжЭ°жЬАзЯ≠иЈѓеЊДпЉМзДґеРОеПВзЕІеЃГж±ВеЗЇйХњеЇ¶жђ°зЯ≠зЪДдЄАжЭ°жЬАзЯ≠иЈѓеЊДпЉМдЊЭжђ°з±їжО®пЉМзЫіеИ∞дїОй°ґзВєvеИ∞еЕґеЃГеРДй°ґзВєзЪДжЬАзЯ≠иЈѓеЊДеЕ®йГ®ж±ВеЗЇдЄЇж≠ҐгАВ
зЃЧж≥ХзЪДеЯЇжЬђжАЭжГ≥жШѓпЉЪ
иЃЊзљЃдЄ§дЄ™й°ґзВєзЪДйЫЖеРИS еТМTпЉЭVпЉНSпЉМйЫЖеРИS дЄ≠е≠ШжФЊеЈ≤жЙЊеИ∞жЬАзЯ≠иЈѓеЊДзЪДй°ґзВєпЉМйЫЖеРИT е≠ШжФЊељУеЙНињШжЬ™жЙЊеИ∞жЬАзЯ≠иЈѓеЊДзЪДй°ґзВєгАВ
еИЭеІЛзКґжАБжЧґпЉМйЫЖеРИS дЄ≠еП™еМЕеРЂжЇРзВєv0пЉМзДґеРОдЄНжЦ≠дїОйЫЖеРИT дЄ≠йАЙеПЦеИ∞й°ґзВєv0 иЈѓеЊДйХњеЇ¶жЬАзЯ≠зЪДй°ґзВєu еК†еЕ•еИ∞йЫЖеРИS дЄ≠пЉМйЫЖеРИS жѓПеК†еЕ•дЄАдЄ™жЦ∞зЪДй°ґзВєuпЉМйГљи¶БдњЃжФєй°ґзВєv0 еИ∞йЫЖеРИT дЄ≠еЙ©дљЩй°ґзВєзЪДжЬАзЯ≠иЈѓеЊДйХњеЇ¶еАЉпЉМйЫЖеРИT дЄ≠еРДй°ґзВєжЦ∞зЪДжЬАзЯ≠иЈѓеЊДйХњеЇ¶еАЉдЄЇеОЯжЭ•зЪДжЬАзЯ≠иЈѓеЊДйХњеЇ¶еАЉдЄОй°ґзВєu зЪДжЬАзЯ≠иЈѓеЊДйХњеЇ¶еАЉеК†дЄКu еИ∞иѓ•й°ґзВєзЪДиЈѓеЊДйХњеЇ¶еАЉдЄ≠зЪДиЊГе∞ПеАЉгАВж≠§ињЗз®ЛдЄНжЦ≠йЗНе§НпЉМзЫіеИ∞йЫЖеРИT зЪДй°ґзВєеЕ®йГ®еК†еЕ•еИ∞S дЄ≠дЄЇж≠ҐгАВ
Dijkstra зЃЧж≥ХзЪДеЃЮзО∞:
й¶ЦеЕИпЉМеЉХињЫдЄАдЄ™иЊЕеК©еРСйЗПDпЉМеЃГзЪДжѓПдЄ™еИЖйЗПD[i] и°®з§ЇељУеЙНжЙАжЙЊеИ∞зЪДдїОеІЛзВєv еИ∞жѓПдЄ™зїИзВєvi зЪДжЬАзЯ≠иЈѓеЊДзЪДйХњеЇ¶гАВеЃГзЪДеИЭжАБдЄЇпЉЪиЛ•дїОv еИ∞vi жЬЙеЉІпЉМеИЩD[i]дЄЇеЉІдЄКзЪДжЭГеАЉпЉЫеР¶еИЩзљЃD[i]дЄЇвИЮгАВжШЊзДґпЉМйХњеЇ¶дЄЇпЉЪ
йВ£дєИпЉМдЄЛдЄАжЭ°йХњеЇ¶жђ°зЯ≠зЪДжЬАзЯ≠жШѓеУ™дЄАжЭ°еСҐпЉЯеБЗиЃЊиѓ•жђ°зЯ≠иЈѓеЊДзЪДзїИзВєжШѓvk пЉМеИЩеПѓжГ≥иАМзЯ•пЉМињЩжЭ°иЈѓеЊДжИЦиАЕжШѓпЉИv, vkпЉЙпЉМжИЦиАЕжШѓпЉИv, vj, vkпЉЙгАВеЃГзЪДйХњеЇ¶жИЦиАЕжШѓдїОv еИ∞vk зЪДеЉІдЄКзЪДжЭГеАЉпЉМжИЦиАЕжШѓD[j]еТМдїОvj еИ∞vk зЪДеЉІдЄКзЪДжЭГеАЉдєЛеТМгАВ
дЊЭжНЃеЙНйЭҐдїЛзїНзЪДзЃЧж≥ХжАЭжГ≥пЉМеЬ®дЄАиИђжГЕеЖµдЄЛпЉМдЄЛдЄАжЭ°йХњеЇ¶жђ°зЯ≠зЪДжЬАзЯ≠иЈѓеЊДзЪДйХњеЇ¶ењЕжШѓпЉЪ
ж†єжНЃдї•дЄКеИЖжЮРпЉМеПѓдї•еЊЧеИ∞е¶ВдЄЛжППињ∞зЪДзЃЧж≥ХпЉЪ
пЉИ1пЉЙеБЗиЃЊзФ®еЄ¶жЭГзЪДйВїжО•зЯ©йШµedges жЭ•и°®з§ЇеЄ¶жЭГжЬЙеРСеЫЊпЉМedges[i][j] и°®з§ЇеЉІгАИvi, vjгАЙдЄКзЪДжЭГеАЉгАВиЛ•гАИvi, vjгАЙдЄНе≠ШеЬ®пЉМеИЩзљЃedges[i][j]дЄЇвИЮпЉИеЬ®иЃ°зЃЧжЬЇдЄКеПѓзФ®еЕБиЃЄзЪДжЬАе§ІеАЉдї£жЫњпЉЙгАВS дЄЇеЈ≤жЙЊеИ∞дїОv еЗЇеПСзЪДжЬАзЯ≠иЈѓеЊДзЪДзїИзВєзЪДйЫЖеРИпЉМеЃГзЪДеИЭеІЛзКґжАБдЄЇз©ЇйЫЖгАВйВ£дєИпЉМдїОv еЗЇеПСеИ∞еЫЊдЄКеЕґдљЩеРДй°ґзВєпЉИзїИзВєпЉЙvi еПѓиГљиЊЊеИ∞жЬАзЯ≠иЈѓеЊДйХњеЇ¶зЪДеИЭеАЉдЄЇпЉЪ
йЗНе§НжУНдљЬпЉИ2пЉЙгАБпЉИ3пЉЙеЕ±n-1 жђ°гАВзФ±ж≠§ж±ВеЊЧдїОv еИ∞еЫЊдЄКеЕґдљЩеРДй°ґзВєзЪДжЬАзЯ≠иЈѓеЊДжШѓдЊЭиЈѓеЊДйХњеЇ¶йАТеҐЮзЪДеЇПеИЧгАВ
е¶ВеЫЊ8.26 жЙАз§ЇдЄАдЄ™жЬЙеРСзљСеЫЊG8 зЪДеЄ¶жЭГйВїжО•зЯ©йШµдЄЇпЉЪ
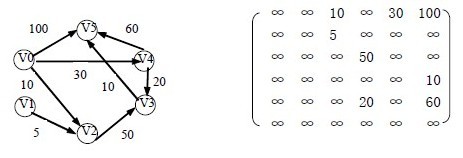
жЬЙеРСзљСеЫЊG8 зЪДеЄ¶жЭГйВїжО•зЯ©йШµ
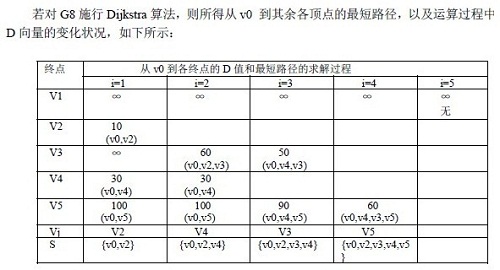
зФ®C иѓ≠и®АжППињ∞зЪДDijkstra зЃЧж≥ХпЉЪ
void ShortestPath_DIJ(MGraph GпЉМint v0пЉМPathMatrix &PпЉМShortPathTable &D){
//зФ®DijkstraзЃЧж≥Хж±ВжЬЙеРСзљСGзЪДv0й°ґзВєеИ∞еЕґдљЩй°ґзВєvзЪДжЬАзЯ≠иЈѓеЊДP[v]еПКеЕґеЄ¶жЭГйХњеЇ¶D[v]гАВ
//иЛ•P[v][w]дЄЇTRUEпЉМеИЩwжШѓдїОv0еИ∞vељУеЙНж±ВеЊЧжЬАзЯ≠иЈѓеЊДдЄКзЪДй°ґзВєгАВ
//final[v]дЄЇTRUEељУдЄФдїЕељУvвИИSпЉМеН≥еЈ≤зїПж±ВеЊЧдїОv0еИ∞vзЪДжЬАзЯ≠иЈѓеЊДгАВ
for(v=0пЉЫ v<G.vexnumпЉЫ ++v) {
final[v]=FALSEпЉЫ D[v]=G.arcs[v0][v]пЉЫ
for(w=0пЉЫ w<G.vexnumпЉЫ ++w) P[v][w] = FALSEпЉЫ//иЃЊз©ЇиЈѓеЊД
if (D[v]<INFINITY) { P[v][v0]=TRUEпЉЫ P[v][v]=TRUEпЉЫ}
}//for
D[v0] = 0пЉЫ final[v0] = TRUEпЉЫ //еИЭеІЛеМЦпЉМv0й°ґзВєе±ЮдЇОSйЫЖ
//еЉАеІЛдЄїеЊ™зОѓпЉМжѓПжђ°ж±ВеЊЧv0еИ∞жЯРдЄ™vй°ґзВєзЪДжЬАзЯ≠иЈѓеЊДпЉМеєґеК†vеИ∞sйЫЖгАВ
for(i=1; i<G.vexnumпЉЫ++i){ //еЕґдљЩG.vexnum-1дЄ™й°ґзВє
min = INFINITYпЉЫ //ељУеЙНжЙАзЯ•з¶їv0й°ґзВєзЪДжЬАињСиЈЭз¶ї
for(w=0пЉЫw<G.vexnumпЉЫ++w)
if(!final[w]) //wй°ґзВєеЬ®V-SдЄ≠
if(D[w]<min){v=wпЉЫmin=D[w]пЉЫ} //wй°ґзВєз¶їv0й°ґзВєжЫіињС
final[v]=TRUEпЉЫ //з¶їv0й°ґзВєжЬАињСзЪДvеК†еЕ•SйЫЖ
for(w=0пЉЫw<G.vexnumпЉЫ++w) //жЫіжЦ∞ељУеЙНжЬАзЯ≠иЈѓеЊДеПКиЈЭз¶ї
if(!final[w]&&(min+G.arcs[v][w]<D[w])){ //дњЃжФєD[w]еТМP[w]
D[w]=min+G.arcs[v][w]пЉЫP[w]=P[v]пЉЫ P[w][w]=TRUEпЉЫ //P[w]=P[v]+[w]
}//if
}//for
}//ShortestPath_DIJ


- 2012-07-15 12:02
- жµПиІИ 994
- иѓДиЃЇ(0)
- жЯ•зЬЛжЫіе§Ъ
еПСи°®иѓДиЃЇ

зЫЄеЕ≥жО®иНР
1.1 йТИеѓєиАГз†ФжХ∞жНЃзїУжЮДзЪДдї£з†Бдє¶еЖЩиІДиМГдї•еПКC дЄОC иѓ≠и®АеЯЇз°А1 1.1.1 иАГз†ФзїЉеРИеЇФзФ®йҐШдЄ≠зЃЧж≥ХиЃЊиЃ°йГ®еИЖзЪДдї£з†Бдє¶еЖЩиІДиМГ1 1.1.2 иАГз†ФдЄ≠зЪДC дЄОC иѓ≠и®АеЯЇз°А3 1.2 зЃЧж≥ХзЪДжЧґйЧіе§НжЭВеЇ¶дЄОз©ЇйЧіе§НжЭВеЇ¶еИЖжЮРеЯЇз°А 12 1.2.1 иАГз†ФдЄ≠зЪДзЃЧж≥ХжЧґйЧі...
TCP/IPиѓ¶иІ£ еНЈ1пЉЪеНПиЃЃ иѓСиАЕеЇП еЙНи®А зђђ1зЂ† ж¶Вињ∞ 1 1.1 еЉХи®А 1 1.2 еИЖе±В 1 1.3 TCP/IPзЪДеИЖе±В 4 1.4 дЇТиБФзљСзЪДеЬ∞еЭА 5 1.5 еЯЯеРНз≥їзїЯ 6 1.6 е∞Би£Е 6 1.7 еИЖзФ® 8 1.8 еЃҐжИЈ-жЬНеК°еЩ®ж®°еЮЛ 8 1.9 зЂѓеП£еПЈ 9 1.10 ж†ЗеЗЖеМЦињЗз®Л 10 ...
гАКиЃ°зЃЧжЬЇзІСе≠¶дЄЫдє¶¬ЈжХ∞жНЃзїУжЮДдїОеЇФзФ®еИ∞еЃЮзО∞(JavaзЙИ)гАЛз≥їзїЯеЬ∞дїЛзїНдЇЖжХ∞жНЃзїУжЮДдї•еПКжХ∞жНЃзїУжЮДдЄОеѓєи±°дєЛйЧізЪДиБФз≥їгАВдЄїи¶БеЖЕеЃєеМЕжЛђпЉЪзЃЧж≥ХжХИзОЗзЪДиЊУеЕ•иІДж®°гАБйШґеТМе§ІOпЉМжХ∞жНЃзїУжЮДзЪДжЧ†еЇПеТМжЬЙеЇПеИЧи°®пЉМйШЯеИЧеТМж†ИеЯЇдЇОжХ∞зїДеТМйУЊи°®зЪДиЃЊиЃ°еЃЮдЊЛ...
зљСзїЬзЇҐдє¶ жХ∞жНЃзїУжЮДйЂШеИЖзђФиЃ∞ дє¶дЄ≠иѓ¶е∞љдЄФйАЪдњЧзЪДжАїзїУдЇЖжЦ∞е§ІзЇ≤иЃ°зЃЧжЬЇиАГз†ФзЪДзЯ•иѓЖзВє еѓєдЇОжХ∞жНЃзїУжЮДеЯЇз°АдЄНе•љзЪДеРМе≠¶пЉМжЧ†зЦСжШѓжЬАдљ≥йАЙжЛ©пЉМ2010еєі жЬАеЕЈељ±еУНеКЫзЪДиЃ°зЃЧжЬЇиАГз†ФиЊЕеѓЉдє¶
жХ∞жНЃзїУжЮДжХЩз®ЛгАЛж†єжНЃйЂШз≠ЙйЩҐж†°иЃ°зЃЧжЬЇдЄУдЄЪжХ∞жНЃзїУжЮДиѓЊз®ЛзЪДжХЩе≠¶е§ІзЇ≤и¶Бж±ВпЉМзїУеРИеНБеєі...гААгАКжХ∞жНЃзїУжЮДжХЩз®ЛгАЛйАВеРИдЇОдљЬдЄЇиЃ°зЃЧжЬЇеПКзЫЄеЕ≥дЄУдЄЪеЇФзФ®еЮЛжЬђзІСжИЦдЄУзІСзЪДжХЩжЭРпЉМдєЯйАВеРИдЇОиЃ°зЃЧжЬЇдЄУдЄЪж∞іеє≥иАГиѓХгАБжИРдЇЇжХЩиВ≤гАБиЗ™е≠¶иАГиѓХзЪДдЇЇеСШеПВиАГгАВ
1.1 жХ∞жНЃзїУжЮДзЪДеЯЇжЬђж¶ВењµеТМжЬѓиѓ≠ 1.1.1 еЉХи®А 1.1.2 жХ∞жНЃзїУжЮДжЬЙеЕ≥ж¶ВењµеПКжЬѓиѓ≠ 1.1.3 жХ∞жНЃзїУжЮДеТМжКљи±°жХ∞жНЃз±їеЮЛпЉИADTпЉЙ 1.2 зЃЧж≥ХжППињ∞дЄОеИЖжЮР 1.2.1 дїАдєИжШѓзЃЧж≥Х 1.2.2 зЃЧж≥ХжППињ∞еЈ•еЕЈвАФвАФпЉ£иѓ≠и®А 1.2.3 зЃЧж≥ХеИЖжЮРжКАжЬѓеИЭж≠•...
жЬђдє¶еЕ±еИЖ4йГ®еИЖпЉМдїОxmlгАБservletгАБjspеТМеЇФзФ®зЪДиІТеЇ¶еРСиѓїиАЕе±Хз§ЇдЇЖjava webеЉАеПСдЄ≠еРДзІНжКАжЬѓзЪДеЇФзФ®пЉМеЊ™еЇПжЄРињЫеЬ∞еЉХеѓЉиѓїиАЕењЂйАЯжОМжП°java webеЉАеПСгАВ. гААжЬђдє¶еЖЕеЃєеЕ®йЭҐпЉМжґµзЫЦдЇЖдїОдЇЛjava webеЉАеПСжЙАеЇФжОМжП°зЪДжЙАжЬЙзЯ•иѓЖгАВеЬ®зЯ•иѓЖзЪДиЃ≤иІ£...
жХ∞жНЃзїУжЮДгАРCиѓ≠и®АзЙИгАС--дЄ•иФЪжХПеЕ®е•ЧиµДжЦЩ: гАКжХ∞жНЃзїУжЮДгАРCиѓ≠и®АзЙИгАС--дЄ•иФЪжХПеРідЉЯж∞СзЉЦиСЧгАЛ.pdf гАКжХ∞жНЃзїУжЮД(Cиѓ≠и®АзЙИ)--дЄ•иФЪжХПеРідЉЯж∞СгАЛйЕНдє¶еЕЙзЫШ гАКжХ∞жНЃзїУжЮДпЉИCиѓ≠и®АзЙИдЄ•иФЪжХПеРідЉЯж∞СпЉЙгАЛйЕНе•ЧзЇѓcдї£з†Б гАКжХ∞жНЃзїУжЮД(cиѓ≠и®АзЙИ--...
иѓЊеРОдє†йҐШзЪДзЉЦз®Лиѓ¶иІ£гАВеѓєдЇОе≠¶дє†жХ∞жНЃзїУжЮДзЪДеРМе≠¶зРЖиІ£жХ∞жНЃзїУжЮДзЪДеЇФзФ®жШѓеЊИжЬЙзФ®зЪД
зђђдЇМйГ®еИЖеИЩжППињ∞еЃЮзО∞ињЩдЇЫRFCзЪДKAMEзЪДжХ∞жНЃзїУжЮДеПКеКЯиГљгАВдє¶зЪДжЬАеРОињШжПРдЊЫдЇЖдЄАдЇЫдЊЛе≠РпЉМиѓіжШОе¶ВдљХзЉЦеЖЩжЧҐеПѓдї•еЬ®IPv4зљСзїЬдЄКињРи°МгАБеПИеПѓдї•еЬ®IPv6зљСзїЬдЄКињРи°МзЪДеПѓзІїж§НеЇФзФ®з®ЛеЇПгАВ гААжЬђдє¶жШѓIPv6зЪДжЭГе®БеПВиАГдє¶пЉМйАВеРИзљСзїЬиЃЊиЃ°еТМеЉАеПСдЇЇеСШ...
гАКUSBеЇФзФ®еЉАеПСеЃЮдЊЛиѓ¶иІ£гАЛеЖЕеЃєеЕ®йЭҐгАБзїУжЮДзіІеЗСгАБеЃЮдЊЛдЄ∞еѓМгАВUSBжО•еП£зЪДеИЭе≠¶иАЕйАЪињЗе≠¶дє†гАКUSBеЇФзФ®еЉАеПСеЃЮдЊЛиѓ¶иІ£гАЛеПѓдї•ењЂйАЯеЕ•йЧ®гАВгАКUSBеЇФзФ®еЉАеПСеЃЮдЊЛиѓ¶иІ£гАЛеѓєеЕЈжЬЙдЄАеЃЪеЉАеПСзїПй™МзЪДиЃЊиЃ°дЇЇеСШпЉМдєЯжЬЙеЊИе•љзЪДеПВиАГдїЈеАЉгАВ
redisзЪДжѓФиЊГиѓ¶зїЖзЪДжЦЗж°£пЉМдљЬзФ®еЬ®дЇОеЇФзФ®жЦєйЭҐдї•еПКдїЦзЪДжХ∞жНЃзїУжЮДз±їеЮЛ
13.1.3 жОИжЭГеЫЊ 251 13.2 иІТиЙ≤зЃ°зРЖ 251 13.2.1 createиѓ≠еП•еИЫеїЇиІТиЙ≤ 252 13.2.2 dropиѓ≠еП•еИ†йЩ§иІТиЙ≤ 252 13.2.3 grantиѓ≠еП•жОИдЇИиІТиЙ≤ 252 13.2.4 revokeиѓ≠еП•еПЦжґИиІТиЙ≤ 253 13.3 жЭГйЩРзЃ°зРЖ 254 13.3.1 grantиѓ≠еП•жОИдЇИ...
гААжЬђзЂ†й¶ЦеЕИеѓєWindowsй©±еК®з®ЛеЇПзЪДдЄ§дЄ™йЗНи¶БжХ∞жНЃзїУжЮДињЫи°МдїЛзїНпЉМеИЖеИЂжШѓй©±еК®еѓєи±°еТМиЃЊе§Зеѓєи±°жХ∞жНЃзїУжЮДгАВеП¶ е§ЦињШи¶БдїЛзїНNTй©±еК®з®ЛеЇПеТМWDMй©±еК®з®ЛеЇПзЪДеЕ•еП£еЗљжХ∞гАБеНЄиљљдЊЛз®ЛгАБеРДзІНIRPжіЊйБ£дЄКеЗљжХ∞з≠ЙгАВ гАА4.1 Windowsй©±еК®з®ЛеЇПдЄ≠йЗНи¶БзЪД...
дЄГгАБзђђдЄГзЂ†дљЬдЄЪз≠Фж°ИжЬђз≥їеИЧеНЪеЃҐдЄЇгАКжХ∞жНЃзїУжЮДгАЛпЉИCиѓ≠и®АзЙИпЉЙзЪДе≠¶дє†зђФиЃ∞пЉИдЄКиѓЊзђФиЃ∞пЉЙпЉМдїЕзФ®дЇОе≠¶дє†дЇ§жµБеТМиЗ™жИСе§Ндє†жХ∞жНЃзїУжЮДеРИйЫЖйУЊжО•пЉЪ гАКжХ∞жНЃзїУжЮДгАЛCиѓ≠и®АзЙИпЉИдЄ•иФЪжХПзЙИпЉЙ еЕ®дє¶
жШУиѓ≠и®АжЇРз†БжШУиѓ≠и®АжХ∞жНЃзїУжЮДи°®зЪДеЇФзФ®жЇРз†Б.rar
2.8 Net/3иБФзљСжХ∞жНЃзїУжЮДе∞ПзїУ 42 2.9 m_copyеТМз∞ЗеЉХзФ®иЃ°жХ∞ 43 2.10 еЕґдїЦйАЙжЛ© 47 2.11 е∞ПзїУ 47 зђђ3зЂ† жО•еП£е±В 49 3.1 еЉХи®А 49 3.2 дї£з†БдїЛзїН 49 3.2.1 еЕ®е±АеПШйЗП 49 3.2.2 SNMPеПШйЗП 50 3.3 ifnetзїУжЮД 51 3.4 ifaddrзїУжЮД 57 ...
жХ∞жНЃзїУжЮДпЉИCиѓ≠и®АзЙИпЉЙеЬ®йАЙжЭРдЄОзЉЦжОТдЄКпЉМиііињСељУеЙНжЩЃйАЪйЂШз≠ЙйЩҐж†°вАЬжХ∞жНЃзїУжЮДвАЭиѓЊз®ЛзЪДзО∞зКґеТМеПСе±ХиґЛеКњпЉМзђ¶еРИжЦ∞з†Фз©ґзФЯиАГиѓХе§ІзЇ≤пЉМеЖЕеЃєйЪЊеЇ¶йАВеЇ¶пЉМз™БеЗЇеЃЮзФ®жАІеТМеЇФзФ®жАІгАВеЕ®дє¶еЕ±7зЂ†пЉМеЖЕеЃєеМЕжЛђзї™иЃЇпЉМзЇњжАІи°®пЉМж†ИеТМйШЯеИЧпЉМдЄ≤гАБжХ∞зїДеТМ...
жЬђжЦЗйАЪзѓЗеЫізїХйБНеОЖеИЧи°®ињЩдЄАдЄїйҐШ,з≥їзїЯиАМиѓ¶е∞љеЬ∞дїЛзїНдЇЖзЫЄеЕ≥зЪДжХ∞жНЃзїУжЮДзЯ•иѓЖгАБйБНеОЖзЃЧж≥ХжАЭжГ≥гАБдї£з†БеЃЮзО∞жЦєж≥Хдї•еПКеЇФзФ®еЬЇжЩѓеИЖжЮРгАВеЕ®йЭҐйШРињ∞дЇЖеИЧи°®ињЩзІНжХ∞жНЃзїУжЮДзЪДзЙєзВє,дї•еПКдљњзФ®еЊ™зОѓеТМињ≠дї£еЩ®йБНеОЖеИЧи°®зЪДдЄ§зІНжЦєеЉП,еєґеИЖжЮРдЇЖзЃЧж≥ХжЧґйЧі...
дє¶еРНпЉЪгАКAndroidеЇХе±ВеЉАеПСжКАжЬѓеЃЮжИШиѓ¶иІ£вАФвАФеЖЕж†ЄгАБзІїж§НеТМй©±еК®гАЛ(зФµе≠РеЈ•дЄЪеЗЇзЙИз§Њ.зОЛжМѓдЄљ)гАВжЬђдє¶дїОеЇХе±ВеОЯзРЖеЉАеІЛиЃ≤иµЈпЉМзїУеРИзЬЯеЃЮзЪДж°ИдЊЛеРСиѓїиАЕиѓ¶зїЖдїЛзїНдЇЖandroidеЖЕж†ЄгАБзІїж§НеТМй©±еК®еЉАеПСзЪДжХідЄ™жµБз®ЛгАВеЕ®дє¶еИЖдЄЇ19зЂ†пЉМдЊЭжђ°иЃ≤иІ£...