下面,我们只涉及MapReduce 1,而不涉及YARN。
当我们在写MapReduce程序的时候,通常,在main函数里,我们会像下面这样做。建立一个Job对象,设置它的JobName,然后配置输入输出路径,设置我们的Mapper类和Reducer类,设置InputFormat和正确的输出类型等等。然后我们会使用job.waitForCompletion()提交到JobTracker,等待job运行并返回,这就是一般的Job设置过程。JobTracker会初始化这个Job,获取输入分片,然后将一个一个的task任务分配给TaskTrackers执行。TaskTracker获取task是通过心跳的返回值得到的,然后TaskTracker就会为收到的task启动一个JVM来运行。
Configuration conf = getConf();
Job job = new Job(conf, "SelectGradeDriver");
job.setJarByClass(SelectGradeDriver.class);
Path in = new Path(args[0]);
Path out = new Path(args[1]);
FileInputFormat.setInputPaths(job, in);
FileOutputFormat.setOutputPath(job, out);
job.setMapperClass(SelectGradeMapper.class);
job.setReducerClass(SelectGradeReducer.class);
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(TextOutputFormat.class);
job.setMapOutputKeyClass(InstituteAndGradeWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(InstituteAndGradeWritable.class);
job.setOutputValueClass(Text.class);
System.exit(job.waitForCompletion(true)? 0 : 1);
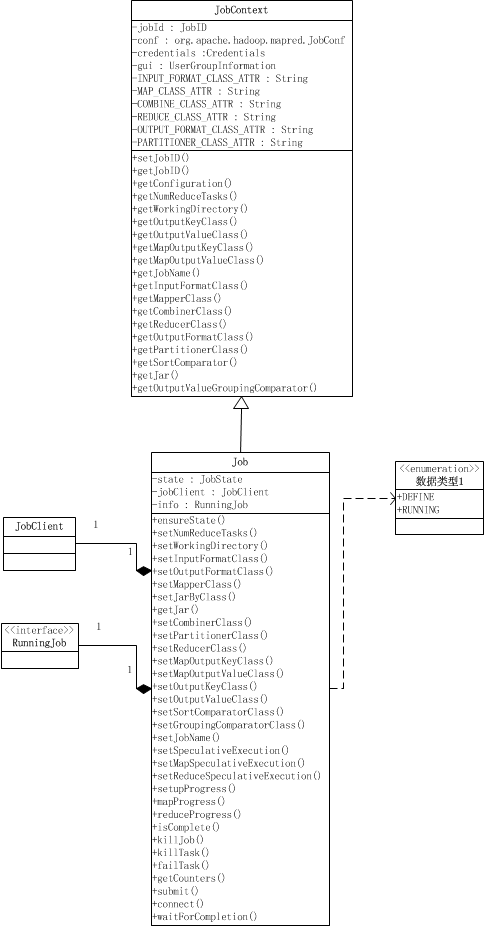
Job其实就是提供配置作业、获取作业配置、以及提交作业的功能,以及跟踪作业进度和控制作业。Job类继承于JobContext类。JobContext提供了获取作业配置的功能,如作业ID,作业的Mapper类,Reducer类,输入格式,输出格式等等,它们除了作业ID之外,都是只读的。 Job类在JobContext的基础上,提供了设置作业配置信息的功能、跟踪进度,以及提交作业的接口和控制作业的方法。
public class Job extends JobContext {
public static enum JobState {DEFINE, RUNNING};
private JobState state = JobState.DEFINE;
private JobClient jobClient;
private RunningJob info;
public float setupProgress() throws IOException {
ensureState(JobState.RUNNING);
return info.setupProgress();
}
public float mapProgress() throws IOException {
ensureState(JobState.RUNNING);
return info.mapProgress();
}
public float reduceProgress() throws IOException {
ensureState(JobState.RUNNING);
return info.reduceProgress();
}
public boolean isComplete() throws IOException {
ensureState(JobState.RUNNING);
return info.isComplete();
}
public boolean isSuccessful() throws IOException {
ensureState(JobState.RUNNING);
return info.isSuccessful();
}
public void killJob() throws IOException {
ensureState(JobState.RUNNING);
info.killJob();
}
public TaskCompletionEvent[] getTaskCompletionEvents(int startFrom
) throws IOException {
ensureState(JobState.RUNNING);
return info.getTaskCompletionEvents(startFrom);
}
public void killTask(TaskAttemptID taskId) throws IOException {
ensureState(JobState.RUNNING);
info.killTask(org.apache.hadoop.mapred.TaskAttemptID.downgrade(taskId),
false);
}
public void failTask(TaskAttemptID taskId) throws IOException {
ensureState(JobState.RUNNING);
info.killTask(org.apache.hadoop.mapred.TaskAttemptID.downgrade(taskId),
true);
}
public Counters getCounters() throws IOException {
ensureState(JobState.RUNNING);
return new Counters(info.getCounters());
}
public void submit() throws IOException, InterruptedException,
ClassNotFoundException {
ensureState(JobState.DEFINE);
setUseNewAPI();
// Connect to the JobTracker and submit the job
connect();
info = jobClient.submitJobInternal(conf);
super.setJobID(info.getID());
state = JobState.RUNNING;
}
private void connect() throws IOException, InterruptedException {
ugi.doAs(new PrivilegedExceptionAction<Object>() {
public Object run() throws IOException {
jobClient = new JobClient((JobConf) getConfiguration());
return null;
}
});
}
public boolean waitForCompletion(boolean verbose
) throws IOException, InterruptedException,
ClassNotFoundException {
if (state == JobState.DEFINE) {
submit();
}
if (verbose) {
jobClient.monitorAndPrintJob(conf, info);
} else {
info.waitForCompletion();
}
return isSuccessful();
}
//lots of setters and others
}
一个Job对象有两种状态,DEFINE和RUNNING,Job对象被创建时的状态时DEFINE,当且仅当Job对象处于DEFINE状态,才可以用来设置作业的一些配置,如Reduce task的数量、InputFormat类、工作的Mapper类,Partitioner类等等,这些设置是通过设置配置信息conf来实现的;当作业通过submit()被提交,就会将这个Job对象的状态设置为RUNNING,这时候作业以及提交了,就不能再设置上面那些参数了,作业处于调度运行阶段。处于RUNNING状态的作业我们可以获取作业、map
task和reduce task的进度,通过代码中的*Progress()获得,这些函数是通过info来获取的,info是RunningJob对象,它是实际在运行的作业的一组获取作业情况的接口,如Progress。
在waitForCompletion()中,首先用submit()提交作业,然后等待info.waitForCompletion()返回作业执行完毕。verbose参数用来决定是否将运行进度等信息输出给用户。submit()首先会检查是否正确使用了new API,这通过setUseNewAPI()检查旧版本的属性是否被设置来实现的[设置是否使用newAPI是因为执行Task时要根据使用的API版本来执行不同版本的MapReduce,在后面讲MapTask时会说到],接着就connect()连接JobTracker并提交。实际提交作业的是一个JobClient对象,提交作业后返回一个RunningJob对象,这个对象可以跟踪作业的进度以及含有由JobTracker设置的作业ID。
getCounter()函数是用来返回这个作业的计数器列表的,计数器被用来收集作业的统计信息,比如失败的map task数量,reduce输出的记录数等等。它包括内置计数器和用户定义的计数器,用户自定义的计数器可以用来收集用户需要的特定信息。计数器首先被每个task定期传输到TaskTracker,最后TaskTracker再传到JobTracker收集起来。这就意味着,计数器是全局的。
关于Counter相关的类,为了保持篇幅简短,放在下一篇讲。
分享到:





相关推荐
【Debug跟踪Hadoop3.0.0源码之MapReduce Job提交流程】第一节 Configuration和Job对象的初始化前言Configuration和Job对象的初始化后记跳转 前言 不得不说,在此前我对阅读源码这件事是拒绝的,一方面也知道自己非读...
Hadoop架构分析之集群结构分析,Hadoop架构分析之HDFS架构分析,Hadoop架构分析之NN和DN原生文档解读,Hadoop MapReduce原理之流程图.Hadoop MapReduce原理之核心类Job和ResourceManager解读.Hadoop MapReduce原理之...
Hadoop架构分析之集群结构分析,Hadoop架构分析之HDFS架构分析,Hadoop架构分析之NN和DN原生文档解读,Hadoop MapReduce原理之流程图.Hadoop MapReduce原理之核心类Job和ResourceManager解读.Hadoop MapReduce原理之...
MapReduce源码分析(主要四大模块,其他表示父目录下的.java文件的总称):1.org.apache.hadoop.mapred(旧版MapReduceAPI):( 1).jobcontrol(job作业直接控制类)(2 ).join :(作业作业中用于模仿数据连接处理...
026 Eclipse导入Hadoop源码项目 027 HDFS 设计目标 028 HDFS 文件系统架构概述 029 HDFS架构之NameNode和DataNode 030 HDFS 架构讲解总结 031 回顾NameNode和DataNode 032 HDFS架构之Client和SNN功能 033 HDFS Shell...
MapReduce Job本地提交过程源码跟踪及分析
MapReduce Job集群提交过程源码跟踪及分析
第一天 hadoop的基本概念 伪分布式hadoop集群安装 hdfs mapreduce 演示 01-hadoop职位需求状况.avi 02-hadoop课程安排.avi 03-hadoop应用场景.avi 04-hadoop对海量数据处理的解决思路.avi 05-hadoop版本选择和...
第一天 hadoop的基本概念 伪分布式hadoop集群安装 hdfs mapreduce 演示 01-hadoop职位需求状况.avi 02-hadoop课程安排.avi 03-hadoop应用场景.avi 04-hadoop对海量数据处理的解决思路.avi 05-hadoop版本选择和...
内容概要: mr执行笔记; mapreduce框架的规范; wc流程.xls; wordcount的伪代码; yarn提交job的源码流程; YARN中提交job的详细流程; 打开流的关键代码; 打开流的调用流程; 日志格式;
NULL 博文链接:https://eastzhang.iteye.com/blog/1775734
NULL 博文链接:https://langyu.iteye.com/blog/962529
MapReduceV1实现中,主要存在3个主要的分布式进程(角色):JobClient、JobTracker和TaskTracker,我们主要是以这三个角色的实际处理活动为主线,并结合源码,分析实际处理流程。下图是《Hadoop权威指南》一书给出的...
Spark是UC Berkeley AMP lab (加州大学伯克利分校的AMP实验室)所开源的类Hadoop MapReduce的通用并行框架,Spark,拥有Hadoop MapReduce所具有的优点;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,...
在MapReduce程序运行的过程中,JobTracker端会在内存中维护一些与Job/Task运行相关的信息,了解这些内容对分析MapReduce程序执行流程的源码会非常有帮助。在编写MapReduce程序时,我们是以Job为单位进行编程处理,一...
不喜欢将该文档称之为“源码分析”,因为本文的主要目的不是去解读实现代码,而是尽量有逻辑地,从设计与实现原理的角度,来理解 job 从产生到执行完成的整个过程,进而去理解整个系统。 讨论系统的设计与实现有很...
不喜欢将该文档称之为“源码分析”,因为本文的主要目的不是去解读实现代码,而是尽量有逻辑地,从设计与实现原理的角度,来理解 job 从产生到执行完成的整个过程,进而去理解整个系统。讨论系统的设计与实现有很...