1.Region定位
在Google的BigTable体系中,tablet的存储地址通过3层目录结构来定位的,如图所示:
注:tablet等同与HBase中的Region
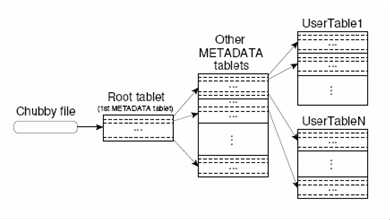
图释说明:
(1)METADATATable
METADATATable是系统预定义的Table,当用户自定义表格被拆分成多个tablet之后,METADATA Table用来存储这些tablet的地址,在目录层级中处于第3层
(2)Root tablet
METADATA表格在分布式存储过程中也会被拆分成多个tablet,其中第一个tablet比较特殊,用来存储其他tablet的地址,称之为Roottablet,在目录层级中处于第2层
(3)Chunbby file
用来存储Roottablet的地址,在目录结构中处于顶层
这样,客户端可通过Chubby file遍历到任何tablet的地址
在HBase中:
Region的概念等同于tablet
.META.表格等同于METADATATable
而-ROOT-表格等同于Chunbby file
这样,客户端可通过-ROOT- Table遍历到任何Region的地址,并把这些地址在本地进行缓存,以加快下次查询效率
2.Region分配
在HBase中,MasterServer负责将Region分配给RegionServer
首先,看一下BigTable中tablet如何分配:
当master机器启动的时候,它会处理如下事情:
(1)首先在Chunbby中获取masterlock,在分布式部署中,系统中只能有一个master处于运行状态,当其获得master锁之后,其他的master机器将会进入等待状态
(2)master会扫描Chunbby目录,以获取处于运行状态的table server(RegionServer)
(3)master会和每一台tabletserver进行通信,来记录哪些tablet已经成功分配
(4)master会扫描METADATA表格,如果发现有tablet不在已分配记录中,则将其分配到合适的tablet server
在HBase中,是通过如下API来完成Region的分配过程:
(1)Master在启动的时候,会去调用AssignmentManager类
(2)AssignmentManager通过查找.META.表格来获取Region信息
(3)如果Region尚未分配,则调用LoadBalancerFactory将其分配,默认的分配器(DefaultLoadBalancer)会将该Region分配给一个随机的RegionServer
(4)更新.META.表格信息
3.数据存储
在HDFS中,HBase的数据存储呈如下目录结构:
<hbase>
|__<table>
|__<region>
|__<columnFamily>
|__<storeFile>
StoreFile是基于Google的SSTable来实现的,每个SSTable相当于一个持久存储的、多维的、可序列化Map,Map的key和value都是可解释型字符数组,可从中提炼出具体的rowKey、timestamp、columnKey和columnValue等信息。
在物理存储上SSTable由多个Block块组成,SSTable记录了每个Block快的索引位置,并且在被访问的时候将这些块索引加载到内存,以便系统快速定位Block块所在磁盘位置。
4.Region Serving
在Google的BigTable体系中,tablet会持久化存储到GFS文件系统中,如图:

图释说明:
(1)当有写操作到达时,系统首先会将信息写入到tablet log,然后把所提交的数据存储在memtable上,这样,tablet log就记录了每次写操作的日志信息以及操作的数据信息,当需要执行undo/redo操作式,可通过遍历查找该tablet log来实现撤销/恢复的功能。
写操作提交之后,数据并没有持久化存储到本地硬盘上,而是放到了memtable里,memtable是存储在内存当中的,当其大小达到一定上限之后,才持久化存储到SSTable File中去,随后进行数据的压缩处理(参考5-数据压缩)
(2)因为memtable也存储了相关的数据信息,而且是写操作提交后的最新信息,所以查询操作的数据来源有两方面,一方面是SSTable Files,另一方面是memtable。
(3)tablet恢复
当tablet数据需要恢复到历史版本时,tablet server首先会查询METADATA表格,从中获取该tablet的元数据信息,包括:
存储该tablet的SSTable文件
Tablet的恢复点(存储在tabletlog中)
随后,tablet server会把要恢复的相关记录加载到内存,根据tablet log所记录的操作日志来重新构建memtable
5.数据压缩
数据压缩主要有3中方式,分别是:
(1)Minor compaction:
当memtable的大小达到一定上限之后便会被系统冻结。此时,一个新的memtable将会创建,而被冻结的memtable将会持久化储存到SSTable文件中去。
(2)Merging compaction:
每一个minor compaction都会生成一个SSTable文件,当minor compaction操作较多时, SSTable文件将会包含很多实体的历史信息,造成数据冗余,解决办法是系统会定期执行merging compaction,将相关SSTable存储的实体进行合并,以保证实体信息处于最新版本,为查询提供方便。
(3)Major compaction:
将所有的SSTable合并成一个SSTable称之为major compaction,Major compaction通常用来回收逻辑上已被删除的数据,以节省磁盘空间。
分享到:





相关推荐
性能比较环境细节资料大小事件表包含500万条记录和90个字段工人3 硬件16个逻辑核心64GB内存(分别为Presto和HBase 16GB内存)4T * 2硬盘 详细信息: : 功能点比较功能性易观其他盐渍表支持的不支持按开始键和结束键...
本书着重介绍了HBase的工作原理和设计架构,同时在实际工作的应用场景上亦着墨很重,大数据的神秘不仅仅在于具体的技术细节,更多的是由于它是个新生事物,很多人并不很清楚大数据的技术架构应如何设计,应用场景...
本文来自于36大数据,这篇文章将会对这些细节进行基本的说明,一方面可以让大家对HBase中Region自动切分有更加深入的理解,另一方面如果想实现类似的功能也可以参考HBase的实现方案。Region自动切分是HBase能够拥有...
本文来自于网络,这篇文章将会对这些细节进行基本的说明,一方面可以让大家对HBase中Region自动切分有更加深入的理解,另一方面如果想实现类似的功能也可以参考HBase的实现方案。最近在学习HBase的使用,并仔细阅读...
HDFS通信部分使用org.apache.hadoop.ipc,可以很快使用RPC.Server.start()构造一个节点,具体业务功能还需自己实现。针对HDFS的业务则为数据流的读写,NameNode/DataNode的通信等。 MapReduce主要在org.apache....
数据的秘密(下):如何分析数据? 前言 上一篇文章中,我们介绍了为什么要关注数据,在本文中我将...如下图 所示: 我们将所有的原始数据都归集到分布式存储 Hbase 中,然后通过配置一些定时的计算任务,就可以 以几
8 Hive Hive是基于Hadoop的⼀个数据仓库⼯具,可以将结构化的数据⽂件映射为⼀张数据库表,并提供简单的SQL查询功能,可以将SQL语 句转换为MapReduce任务进⾏运⾏。 其优点是学习成本低,可以通过类SQL语句快速实现...
⼤数据技术之Spark Spark架构图 Spark Core:包含Spark的基本功能;尤其是定义RDD的API、操作以及这两者上的动作。其他Spark的库都是构建在RDD和Spark Core 之上的。 Spark SQL:提供通过Apache Hi